SciPy 中的通用非均勻隨機數採樣#
SciPy 提供了許多通用非均勻隨機數產生器的介面,用於從各種單變量連續和離散分佈中採樣隨機變量。快速 C 程式庫 UNU.RAN 的實作被用於提高速度和效能。請查看 UNU.RAN 的文件,以深入了解這些方法的解釋。在撰寫本教學和所有產生器的文件時,大量參考了該文件。
簡介#
隨機變量生成是研究演算法的小領域,旨在從各種分佈中生成隨機變量。通常假設可以使用均勻隨機數產生器。這是一個程式,用於產生獨立且恆等分佈的連續 U(0,1) 隨機變量(即區間 (0,1) 上的均勻隨機變量)序列。當然,現實世界的電腦永遠無法產生理想的隨機數,也無法產生任意精度的數字,但最先進的均勻隨機數產生器已接近此目標。因此,隨機變量生成處理將此類 U(0,1) 隨機數序列轉換為非均勻隨機變量的問題。這些方法是通用的,並以黑箱方式運作。
一些方法如下:
反演法:當累積分布函數的反函數 \(F^{-1}\) 已知時,隨機變量生成很容易。我們只需產生一個均勻 U(0,1) 分佈的隨機數 U,並傳回 \(X = F^{-1}(U)\)。由於反函數的封閉形式解很少可用,因此通常需要依賴反函數的近似值(例如
scipy.special.ndtri、scipy.special.stdtrit)。一般而言,特殊函數的實作與 UNU.RAN 中的反演法相比相當慢。拒絕法:拒絕法,通常稱為接受-拒絕法,是由 John von Neumann 在 1951 年提出的[1]。它涉及計算 PDF 的上限(也稱為帽函數),並使用反演法從此上限生成隨機變量,例如 Y。然後,可以在 0 到上限在 Y 處的值之間繪製均勻隨機數。如果此數字小於 Y 處的 PDF,則傳回樣本,否則拒絕它。請參閱
scipy.stats.sampling.TransformedDensityRejection。比率均勻法:這是一種接受-拒絕法,它使用最小邊界矩形來建構帽函數。請參閱
scipy.stats.sampling.RatioUniforms。離散分佈的反演:與連續情況相比,差異在於 \(F\) 現在是階梯函數。為了在電腦中實現這一點,使用了搜尋演算法,其中最簡單的是循序搜尋。從 U(0, 1) 生成一個均勻隨機數,並將機率相加,直到累積機率超過均勻隨機數。發生此情況的索引是所需的隨機變量並傳回。
有關這些演算法的更多詳細資訊,請參閱 UNU.RAN 使用者手冊的附錄。
在生成分佈的隨機變量時,有兩個因素對於確定產生器的速度很重要:設定步驟和實際採樣。根據情況,不同的產生器可能是最佳的。例如,如果需要從具有固定形狀參數的給定分佈中重複繪製大型樣本,則如果採樣速度很快,則可以接受較慢的設定。這稱為固定參數情況。如果目標是為不同的形狀參數(變動參數情況)生成分佈樣本,則對於每個參數都需要重複的昂貴設定將導致非常差的效能。在這種情況下,快速設定對於實現良好的效能至關重要。下表顯示了不同方法的設定和採樣速度的概述。
連續分佈的方法 |
必要輸入 |
選用輸入 |
設定速度 |
採樣速度 |
|---|---|---|---|---|
pdf, dpdf |
無 |
慢 |
快 |
|
cdf |
pdf, dpdf |
(非常)慢 |
(非常)快 |
|
cdf |
(非常)慢 |
(非常)快 |
||
無 |
快 |
慢 |
其中
pdf:機率密度函數
dpdf:pdf 的導數
cdf:累積分布函數
為了以最小的努力將數值反演法 NumericalInversePolynomial 應用於 SciPy 中的大量連續分佈,請查看 scipy.stats.sampling.FastGeneratorInversion。
離散分佈的方法 |
必要輸入 |
選用輸入 |
設定速度 |
採樣速度 |
|---|---|---|---|---|
pv |
pmf |
慢 |
非常快 |
|
pv |
pmf |
慢 |
非常快 |
其中
pv:機率向量
pmf:機率質量函數
介面的基本概念#
每個產生器都需要先設定,然後才能開始從中採樣。這可以通過實例化該類別的物件來完成。大多數產生器都將分佈物件作為輸入,其中包含所需方法(如 PDF、CDF 等)的實作。除了分佈物件之外,還可以傳遞用於設定產生器的參數。也可以使用 domain 參數截斷分佈。所有產生器都需要一串均勻隨機數,這些隨機數被轉換為給定分佈的隨機變量。這是通過傳遞帶有 NumPy BitGenerator 作為均勻隨機數產生器的 random_state 參數來完成的。random_state 可以是整數、numpy.random.Generator 或 numpy.random.RandomState。
警告
不建議使用 NumPy < 1.19.0,因為它沒有用於生成均勻隨機數的快速 Cython API,並且對於實際使用來說可能太慢。
所有產生器都有一個通用的 rvs 方法,可用於從給定分佈中繪製樣本。
下面顯示了此介面的範例
from scipy.stats.sampling import TransformedDensityRejection
from math import exp
import numpy as np
class StandardNormal:
def pdf(self, x: float) -> float:
# note that the normalization constant isn't required
return exp(-0.5 * x*x)
def dpdf(self, x: float) -> float:
return -x * exp(-0.5 * x*x)
dist = StandardNormal()
urng = np.random.default_rng()
rng = TransformedDensityRejection(dist, random_state=urng)
如範例所示,我們首先初始化一個分佈物件,其中包含產生器所需方法的實作。在我們的案例中,我們使用 TransformedDensityRejection (TDR) 方法,該方法需要 PDF 及其關於 x (即變量)的導數。
注意
請注意,分佈的方法(即 pdf、dpdf 等)不需要向量化。它們應該接受並傳回浮點數。
注意
也可以將 SciPy 分佈作為引數傳遞。但是,請注意,該物件並不總是具有某些產生器所需的所有資訊,例如 TDR 方法的 PDF 導數。依賴 SciPy 分佈也可能會降低效能,因為方法(如 pdf 和 cdf)的向量化。在這兩種情況下,都可以實作自訂分佈物件,其中包含所有必要的方法,並且不向量化,如上面的範例所示。如果想要將數值反演法應用於 SciPy 中定義的分佈,也請查看 scipy.stats.sampling.FastGeneratorInversion。
在上面的範例中,我們設定了 TransformedDensityRejection 方法的物件,以從標準常態分佈中採樣。現在,我們可以通過呼叫 rvs 方法開始從我們的分佈中採樣
rng.rvs()
-1.0494228051028878
rng.rvs((5, 3))
array([[-0.79011734, -0.97364192, 1.30965235],
[ 1.77777466, -0.73648314, 0.20012238],
[ 0.28720556, -0.26408585, -0.01241964],
[-1.43792314, 0.60251365, 1.44168353],
[-0.67256502, -1.73323039, -1.30021512]])
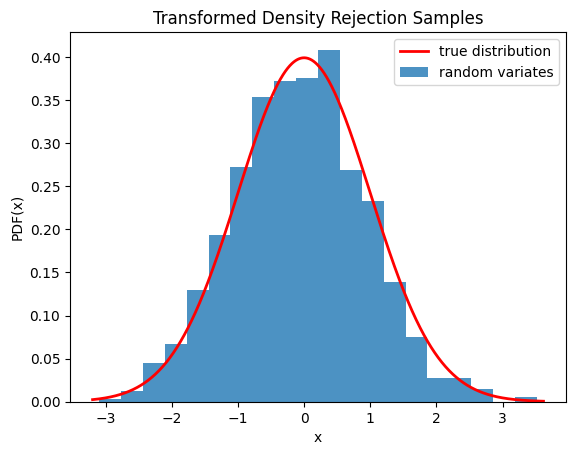
我們還可以通過視覺化樣本的直方圖來檢查樣本是否是從正確的分佈中抽取的
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from scipy.stats.sampling import TransformedDensityRejection
from math import exp
class StandardNormal:
def pdf(self, x: float) -> float:
# note that the normalization constant isn't required
return exp(-0.5 * x*x)
def dpdf(self, x: float) -> float:
return -x * exp(-0.5 * x*x)
dist = StandardNormal()
urng = np.random.default_rng()
rng = TransformedDensityRejection(dist, random_state=urng)
rvs = rng.rvs(size=1000)
x = np.linspace(rvs.min()-0.1, rvs.max()+0.1, num=1000)
fx = norm.pdf(x)
plt.plot(x, fx, 'r-', lw=2, label='true distribution')
plt.hist(rvs, bins=20, density=True, alpha=0.8, label='random variates')
plt.xlabel('x')
plt.ylabel('PDF(x)')
plt.title('Transformed Density Rejection Samples')
plt.legend()
plt.show()
注意
請注意 scipy.stats 中存在的分佈的 rvs 方法與這些產生器提供的方法之間的差異。UNU.RAN 產生器必須被認為是獨立的,因為在某種意義上,它們通常會產生與 scipy.stats 中等效分佈針對任何種子產生的隨機數流不同的隨機數流。scipy.stats.rv_continuous 中的 rvs 實作通常依賴於 NumPy 模組 numpy.random 用於眾所周知的分佈(例如,常態分佈、beta 分佈)和其他分佈的轉換(例如,常態反高斯 scipy.stats.norminvgauss 和對數常態 scipy.stats.lognorm 分佈)。如果未實作特定方法,scipy.stats.rv_continuous 預設為 CDF 的數值反演法,該方法非常慢。由於 UNU.RAN 以不同於 SciPy 或 NumPy 的方式轉換均勻隨機數,因此即使對於相同的均勻隨機數流,產生的 RV 流也不同。例如,即使對於相同的 random_state,SciPy 的 scipy.stats.norm 和 UNU.RAN 的 TransformedDensityRejection 的隨機數流也不會相同
from scipy.stats.sampling import norm, TransformedDensityRejection
from copy import copy
dist = StandardNormal()
urng1 = np.random.default_rng()
urng1_copy = copy(urng1)
rng = TransformedDensityRejection(dist, random_state=urng1)
rng.rvs()
# -1.526829048388144
norm.rvs(random_state=urng1_copy)
# 1.3194816698862635
我們可以傳遞 domain 參數來截斷分佈
rng = TransformedDensityRejection(dist, domain=(-1, 1), random_state=urng)
rng.rvs((5, 3))
array([[-0.34700433, 0.78860855, 0.25656489],
[-0.12975904, 0.20558451, 0.98210181],
[-0.28086258, 0.75469075, -0.32780586],
[ 0.1158423 , 0.09094358, -0.30694274],
[-0.95995934, 0.80675682, 0.19385288]])
無效和錯誤的引數由 SciPy 或 UNU.RAN 處理。後者拋出 UNURANError,它遵循通用格式
UNURANError: [objid: <object id>] <error code>: <reason> => <type of error>
其中
<object id>是 UNU.RAN 給定的物件 ID<error code>是表示錯誤類型的錯誤代碼。<reason>是發生錯誤的原因。<type of error>是錯誤類型的簡短描述。
<reason> 顯示了導致錯誤的原因。就其本身而言,它應該包含足夠的資訊來幫助除錯錯誤。此外,<error id> 和 <type of error> 可用於調查 UNU.RAN 中不同類型的錯誤。所有錯誤代碼及其描述的完整列表可以在 UNU.RAN 使用者手冊的第 8.4 節中找到。
下面顯示了 UNU.RAN 產生的錯誤範例
UNURANError: [objid: TDR.003] 50 : PDF(x) < 0.! => (generator) (possible) invalid data
這表示 UNU.RAN 無法初始化 ID 為 TDR.003 的物件,因為 PDF < 0,即為負數。這屬於「產生器的可能無效資料」類型,錯誤代碼為 50。
UNU.RAN 拋出的警告也遵循相同的格式。