NumericalInversePolynomial#
- class scipy.stats.sampling.NumericalInversePolynomial(dist, *, mode=None, center=None, domain=None, order=5, u_resolution=1e-10, random_state=None)#
基於多項式內插的 CDF 反函數 (PINV)。
PINV 是數值反演的一種變體,其中反函數 CDF 使用牛頓內插公式逼近。
[0,1]區間被分割成幾個子區間。在每個子區間中,反函數 CDF 在節點(CDF(x),x)上構建,其中x是此子區間中的某些點。如果給定了 PDF,則使用具有 5 個點的自適應高斯-洛巴托積分,從給定的 PDF 數值計算 CDF。子區間會持續分割,直到達到請求的精度目標。此方法不是精確的,因為它僅產生逼近分佈的隨機變量。然而,最大容許的逼近誤差可以設定為解析度(但當然受限於機器精度)。我們使用 u 誤差
|U - CDF(X)|來衡量誤差,其中X是對應於分位數U的近似百分位數,即X = approx_ppf(U)。我們稱最大容許的 u 誤差為演算法的 u 解析度。內插多項式的階數和 u 解析度都可以選擇。請注意,非常小的 u 解析度值是可能的,但會增加設定步驟的成本。
內插多項式必須在設定步驟中計算。但是,它僅適用於具有有界域的分佈;對於具有無界域的分佈,尾部會被截斷,使得尾部區域的機率與給定的 u 解析度相比很小。
只有當 PDF 是單峰的,或者當 PDF 在兩個峰值之間不消失時,內插多項式的建構才有效。
給定的分佈有一些限制
分佈的支撐集(即 PDF 嚴格為正的區域)必須是連通的。實際上,這表示 PDF「不太小」的區域必須是連通的。單峰密度滿足此條件。如果違反此條件,則可能會截斷分佈的域。
當 PDF 以數值方式積分時,給定的 PDF 必須是連續的,並且應該是平滑的。
PDF 必須是有界的。
當分佈具有重尾(因為反函數 CDF 在 0 或 1 處變得非常陡峭)且請求的 u 解析度非常小時,該演算法會遇到問題。例如,當請求的 u 解析度小於 1.e-12 時,柯西分佈很可能出現此問題。
- 參數:
- distobject
具有
pdf或logpdf方法的類別實例,可選地具有cdf方法。pdf:分佈的 PDF。PDF 的簽名預期為:def pdf(self, x: float) -> float,即 PDF 應接受 Python float 並返回 Python float。它不需要積分為 1,即 PDF 不需要正規化。此方法是可選的,但需要指定pdf或logpdf之一。如果兩者都給定,則使用logpdf。logpdf:分佈 PDF 的對數。簽名與pdf相同。同樣,PDF 正規化常數的對數可以忽略。此方法是可選的,但需要指定pdf或logpdf之一。如果兩者都給定,則使用logpdf。cdf:分佈的 CDF。此方法是可選的。如果提供,則啟用「u 誤差」的計算。請參閱u_error。必須具有與 PDF 相同的簽名。
- modefloat,可選
分佈的(精確)眾數。預設值為
None。- centerfloat,可選
分佈的眾數或平均值的近似位置。此位置提供有關 PDF 主要部分的一些資訊,並用於避免數值問題。預設值為
None。- domain長度為 2 的 list 或 tuple,可選
分佈的支撐集。預設值為
None。當None時如果分佈物件 dist 提供
support方法,則使用它來設定分佈的域。否則,支撐集假定為 \((-\infty, \infty)\)。
- orderint,可選
內插多項式的階數。有效階數介於 3 到 17 之間。較高的階數會減少逼近的區間數。預設值為 5。
- u_resolutionfloat,可選
設定最大容許的 u 誤差。u_resolution 的值必須至少為 1.e-15,最多為 1.e-5。請注意,大多數均勻隨機數來源的解析度為 2-32= 2.3e-10。因此,值 1.e-10 會產生可以稱為精確的反演演算法。對於大多數模擬,稍大的最大誤差值也已足夠。預設值為 1e-10。
- random_state{None, int,
numpy.random.Generator, NumPy 隨機數生成器或用於產生均勻隨機數流的底層 NumPy 隨機數生成器的種子。如果 random_state 為 None(或 np.random),則使用
numpy.random.RandomState單例。如果 random_state 是 int,則使用新的RandomState實例,並以 random_state 作為種子。如果 random_state 已經是Generator或RandomState實例,則使用該實例。
參考文獻
[1]Derflinger, Gerhard, Wolfgang Hörmann, and Josef Leydold. “Random variate generation by numerical inversion when only the density is known.” ACM Transactions on Modeling and Computer Simulation (TOMACS) 20.4 (2010): 1-25.
[2]UNU.RAN reference manual, Section 5.3.12, “PINV - Polynomial interpolation based INVersion of CDF”, https://statmath.wu.ac.at/software/unuran/doc/unuran.html#PINV
範例
>>> from scipy.stats.sampling import NumericalInversePolynomial >>> from scipy.stats import norm >>> import numpy as np
要建立從標準常態分佈取樣的生成器,請執行
>>> class StandardNormal: ... def pdf(self, x): ... return np.exp(-0.5 * x*x) ... >>> dist = StandardNormal() >>> urng = np.random.default_rng() >>> rng = NumericalInversePolynomial(dist, random_state=urng)
一旦建立生成器,就可以透過呼叫
rvs方法從分佈中繪製樣本>>> rng.rvs() -1.5244996276336318
為了檢查隨機變量是否緊密遵循給定的分佈,我們可以查看其直方圖
>>> import matplotlib.pyplot as plt >>> rvs = rng.rvs(10000) >>> x = np.linspace(rvs.min()-0.1, rvs.max()+0.1, 1000) >>> fx = norm.pdf(x) >>> plt.plot(x, fx, 'r-', lw=2, label='true distribution') >>> plt.hist(rvs, bins=20, density=True, alpha=0.8, label='random variates') >>> plt.xlabel('x') >>> plt.ylabel('PDF(x)') >>> plt.title('Numerical Inverse Polynomial Samples') >>> plt.legend() >>> plt.show()
如果精確的 CDF 在設定期間可用,則可以估計逼近 PPF 的 u 誤差。為此,在初始化期間傳遞具有分佈精確 CDF 的 dist 物件
>>> from scipy.special import ndtr >>> class StandardNormal: ... def pdf(self, x): ... return np.exp(-0.5 * x*x) ... def cdf(self, x): ... return ndtr(x) ... >>> dist = StandardNormal() >>> urng = np.random.default_rng() >>> rng = NumericalInversePolynomial(dist, random_state=urng)
現在,可以透過呼叫
u_error方法來估計 u 誤差。它執行蒙地卡羅模擬來估計 u 誤差。預設情況下,使用 100000 個樣本。若要變更此設定,您可以將樣本數作為引數傳遞>>> rng.u_error(sample_size=1000000) # uses one million samples UError(max_error=8.785994154436594e-11, mean_absolute_error=2.930890027826552e-11)
這會傳回一個 namedtuple,其中包含最大 u 誤差和平均絕對 u 誤差。
可以透過降低 u 解析度(最大容許的 u 誤差)來減少 u 誤差
>>> urng = np.random.default_rng() >>> rng = NumericalInversePolynomial(dist, u_resolution=1.e-12, random_state=urng) >>> rng.u_error(sample_size=1000000) UError(max_error=9.07496300328603e-13, mean_absolute_error=3.5255644517257716e-13)
請注意,這會增加設定時間的成本。
可以透過呼叫
ppf方法來評估逼近的 PPF>>> rng.ppf(0.975) 1.9599639857012559 >>> norm.ppf(0.975) 1.959963984540054
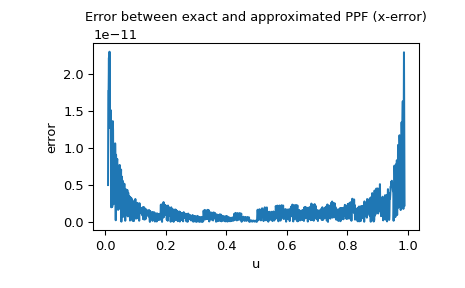
由於常態分佈的 PPF 可作為特殊函數使用,我們也可以檢查 x 誤差,即逼近的 PPF 和精確 PPF 之間的差異
>>> import matplotlib.pyplot as plt >>> u = np.linspace(0.01, 0.99, 1000) >>> approxppf = rng.ppf(u) >>> exactppf = norm.ppf(u) >>> error = np.abs(exactppf - approxppf) >>> plt.plot(u, error) >>> plt.xlabel('u') >>> plt.ylabel('error') >>> plt.title('Error between exact and approximated PPF (x-error)') >>> plt.show()
- 屬性:
intervals取得計算中使用的區間數。
方法
cdf(x)給定分佈的逼近累積分布函數。
ppf(u)給定分佈的逼近 PPF。
qrvs([size, d, qmc_engine])給定 RV 的準隨機變量。
rvs([size, random_state])從分佈中取樣。
set_random_state([random_state])設定底層均勻隨機數生成器。
u_error([sample_size])使用蒙地卡羅模擬估計逼近的 u 誤差。