TransformedDensityRejection#
- class scipy.stats.sampling.TransformedDensityRejection(dist, *, mode=None, center=None, domain=None, c=-0.5, construction_points=30, use_dars=True, max_squeeze_hat_ratio=0.99, random_state=None)#
轉換密度拒絕 (TDR) 方法。
TDR 是一種接受/拒絕方法,它使用轉換密度的凹性來自動建構帽函數和擠壓函數。與專用於該分佈的演算法相比,大多數通用演算法都非常慢。快速的演算法設置緩慢且需要大型表格。這種通用方法的目的是提供一種不太慢且僅需簡短設置的演算法。此方法可以應用於具有 T 凹密度函數的單變量和單峰連續分佈。 有關更多詳細信息,請參閱 [1] 和 [2]。
- 參數:
- dist物件
具有
pdf和dpdf方法的類別實例。pdf: 分佈的 PDF。PDF 的簽名預期為:def pdf(self, x: float) -> float。即 PDF 應接受 Python float 並傳回 Python float。它不需要積分為 1,即 PDF 不需要正規化。dpdf: PDF 相對於 x(即變數)的導數。必須與 PDF 具有相同的簽名。
- modefloat,選填
分佈的(精確)眾數。預設值為
None。- centerfloat,選填
分佈的眾數或平均值的近似位置。此位置提供有關 PDF 主要部分的一些資訊,並用於避免數值問題。預設值為
None。- domain長度為 2 的 list 或 tuple,選填
分佈的支援域。預設值為
None。當None時如果分佈物件 dist 提供
support方法,則使用它來設定分佈的域。否則,支援域假定為 \((-\infty, \infty)\)。
- c{-0.5, 0.},選填
為轉換函數
T設定參數c。預設值為 -0.5。PDF 的轉換必須是凹函數,才能建構帽函數。這種 PDF 稱為 T 凹函數。目前支援以下轉換\[\begin{split}c = 0.: T(x) &= \log(x)\\ c = -0.5: T(x) &= \frac{1}{\sqrt{x}} \text{ (預設)}\end{split}\]- construction_pointsint 或 array_like,選填
如果是整數,則定義建構點的數量。如果是類陣列,則陣列的元素用作建構點。預設值為 30。
- use_darsbool,選填
如果為 True,則在設定中使用「去隨機化自適應拒絕取樣」(DARS)。 有關 DARS 演算法的詳細信息,請參閱 [1]。預設值為 True。
- max_squeeze_hat_ratiofloat,選填
設定比率上限(擠壓函數下方的面積)/(帽函數下方的面積)。它必須是介於 0 和 1 之間的數字。預設值為 0.99。
- random_state{None, int,
numpy.random.Generator, NumPy 隨機數生成器或用於產生均勻分佈隨機數流的底層 NumPy 隨機數生成器的種子。如果 random_state 為 None(或 np.random),則使用
numpy.random.RandomState單例。如果 random_state 是 int,則使用新的RandomState實例,並以 random_state 為種子。如果 random_state 已經是Generator或RandomState實例,則使用該實例。
參考文獻
[1] (1,2)UNU.RAN 參考手冊,第 5.3.16 節,「TDR - 轉換密度拒絕」,http://statmath.wu.ac.at/software/unuran/doc/unuran.html#TDR
[2]Hörmann, Wolfgang. “用於從 T 凹分佈中取樣的拒絕技術。” ACM Transactions on Mathematical Software (TOMS) 21.2 (1995): 182-193
[3]W.R. Gilks 和 P. Wild (1992)。用於 Gibbs 取樣的自適應拒絕取樣,Applied Statistics 41, pp. 337-348。
範例
>>> from scipy.stats.sampling import TransformedDensityRejection >>> import numpy as np
假設我們有一個密度
\[\begin{split}f(x) = \begin{cases} 1 - x^2, & -1 \leq x \leq 1 \\ 0, & \text{otherwise} \end{cases}\end{split}\]此密度函數的導數為
\[\begin{split}\frac{df(x)}{dx} = \begin{cases} -2x, & -1 \leq x \leq 1 \\ 0, & \text{otherwise} \end{cases}\end{split}\]請注意,PDF 不積分為 1。由於這是一種基於拒絕的方法,因此我們不需要正規化的 PDF。若要初始化產生器,我們可以使用
>>> urng = np.random.default_rng() >>> class MyDist: ... def pdf(self, x): ... return 1-x*x ... def dpdf(self, x): ... return -2*x ... >>> dist = MyDist() >>> rng = TransformedDensityRejection(dist, domain=(-1, 1), ... random_state=urng)
域對於截斷分佈非常有用,但為了避免每次都將其傳遞給建構函式,可以透過在分佈物件 (dist) 中提供 support 方法來設定預設域
>>> class MyDist: ... def pdf(self, x): ... return 1-x*x ... def dpdf(self, x): ... return -2*x ... def support(self): ... return (-1, 1) ... >>> dist = MyDist() >>> rng = TransformedDensityRejection(dist, random_state=urng)
現在,我們可以使用
rvs方法從分佈中產生樣本>>> rvs = rng.rvs(1000)
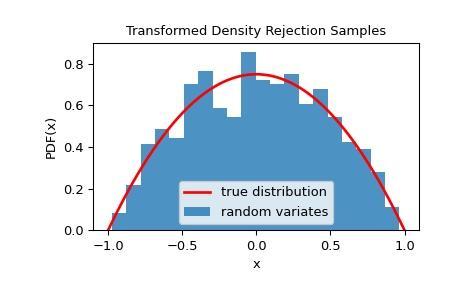
我們可以透過視覺化其直方圖來檢查樣本是否來自給定的分佈
>>> import matplotlib.pyplot as plt >>> x = np.linspace(-1, 1, 1000) >>> fx = 3/4 * dist.pdf(x) # 3/4 is the normalizing constant >>> plt.plot(x, fx, 'r-', lw=2, label='true distribution') >>> plt.hist(rvs, bins=20, density=True, alpha=0.8, label='random variates') >>> plt.xlabel('x') >>> plt.ylabel('PDF(x)') >>> plt.title('Transformed Density Rejection Samples') >>> plt.legend() >>> plt.show()
- 屬性:
hat_area取得產生器帽函數下方的面積。
squeeze_area取得產生器擠壓函數下方的面積。
squeeze_hat_ratio取得產生器目前的比率(擠壓函數下方的面積)/(帽函數下方的面積)。
方法
ppf_hat(u)在 u 處評估帽函數分佈的 CDF 反函數。
rvs([size, random_state])從分佈中取樣。
set_random_state([random_state])設定底層均勻分佈隨機數產生器。