NumericalInverseHermite#
- class scipy.stats.sampling.NumericalInverseHermite(dist, *, domain=None, order=3, u_resolution=1e-12, construction_points=None, random_state=None)#
基於 Hermite 插值的 CDF 反演 (HINV)。
HINV 是數值反演的一種變體,其中反向 CDF 使用 Hermite 插值來近似,即區間 [0,1] 被分割成若干個子區間,並且在每個區間中,反向 CDF 由通過 CDF 和 PDF 在區間邊界的值構建的多項式來近似。這使得通過分割特定區間來提高精度成為可能,而無需在不受影響的區間中重新計算。實作了三種樣條曲線類型:線性、三次和五次插值。對於線性插值,只需要 CDF。三次插值還需要 PDF,而五次插值則需要 PDF 及其導數。
這些樣條曲線必須在設定步驟中計算。但是,它僅適用於具有有界域的分佈;對於具有無界域的分佈,尾部被截斷,使得尾部區域的機率相對於給定的 u 解析度而言很小。
該方法不是精確的,因為它僅產生近似分佈的隨機變數。然而,「u 方向」的最大數值誤差(即 `
|U - CDF(X)|` 其中 `X` 是對應於分位數 `U` 的近似百分位數,即 `X = approx_ppf(U)`)可以設定為所需的解析度(在機器精度範圍內)。請注意,非常小的 u 解析度值是可能的,但可能會增加設定步驟的成本。- 參數:
- dist物件
具有 `
cdf` 以及選擇性的 `pdf` 和 `dpdf` 方法的類別實例。`
cdf`: 分佈的 CDF。CDF 的簽名預期為:`def cdf(self, x: float) -> float`。即 CDF 應接受 Python 浮點數並返回 Python 浮點數。`
pdf`: 分佈的 PDF。當 `order=1` 時,此方法是選填的。必須具有與 PDF 相同的簽名。`
dpdf`: PDF 相對於變數(即 `x`)的導數。當 `order=1` 或 `order=3` 時,此方法是選填的。必須具有與 CDF 相同的簽名。
- domain長度為 2 的列表或元組,選填
分佈的支撐域。預設值為 `
None`。當 `None` 時如果分佈物件 dist 提供 `
support` 方法,則使用它來設定分佈的域。否則,支撐域被假定為 \((-\infty, \infty)\)。
- order整數,預設值:`
3` 設定 Hermite 插值的階數。有效階數為 1、3 和 5。有效階數為 1、3 和 5。請注意,大於 1 的階數需要分佈的密度,而大於 3 的階數甚至需要密度的導數。使用階數 1 會導致大多數分佈產生大量的區間,因此不建議使用。如果 u 方向的最大誤差非常小(例如小於 1.e-10),則建議使用階數 5,因為只要沒有極點或重尾,它會導致更少的設計點。
- u_resolution浮點數,預設值:`
1e-12` 設定最大容許 u 誤差。請注意,大多數均勻分佈隨機數來源的解析度為 2-32= 2.3e-10。因此,值 1.e-10 會產生一個可以稱為精確的反演演算法。對於大多數模擬,稍大的最大誤差值也足夠。預設值為 1e-12。
- construction_points類陣列,選填
設定 Hermite 插值的起始建構點(節點)。由於可能的最大誤差僅在設定中估計,因此可能有必要設定一些特殊的設計點來計算 Hermite 插值,以保證最大 u 誤差不會大於期望值。此類點是密度不可微分或具有局部極值的點。
- random_state{None, 整數,
numpy.random.Generator, NumPy 隨機數生成器或用於底層 NumPy 隨機數生成器的種子,用於生成均勻分佈隨機數流。如果 random_state 為 None(或 np.random),則使用
numpy.random.RandomState單例。如果 random_state 是整數,則使用新的 `RandomState` 實例,並以 random_state 作為種子。如果 random_state 已經是 `Generator` 或 `RandomState` 實例,則使用該實例。
註解
NumericalInverseHermite使用 Hermite 樣條曲線近似連續統計分佈的 CDF 反函數。Hermite 樣條曲線的階數可以通過傳遞 order 參數來指定。如 [1] 中所述,它首先評估分佈的 PDF 和 CDF 在分佈支撐域內的百分位數網格 `
x` 處的值。它使用結果擬合 Hermite 樣條曲線 `H`,使得 `H(p) == x`,其中 `p` 是與百分位數 `x` 對應的百分位數陣列。因此,樣條曲線在百分位數 `p` 處以機器精度近似分佈的 CDF 反函數,但通常,樣條曲線在百分位數點之間的中點處不會那麼準確p_mid = (p[:-1] + p[1:])/2
因此,根據需要細化百分位數網格以減少最大「u 誤差」
u_error = np.max(np.abs(dist.cdf(H(p_mid)) - p_mid))
低於指定的容差 u_resolution。當達到所需的容差或當下一次細化後的網格區間數可能超過最大允許區間數(即 100000)時,細化停止。
參考文獻
[1]Hörmann, Wolfgang, 和 Josef Leydold。「Continuous random variate generation by fast numerical inversion.」ACM Transactions on Modeling and Computer Simulation (TOMACS) 13.4 (2003): 347-362.
[2]UNU.RAN reference manual, Section 5.3.5, “HINV - Hermite interpolation based INVersion of CDF”, https://statmath.wu.ac.at/software/unuran/doc/unuran.html#HINV
範例
>>> from scipy.stats.sampling import NumericalInverseHermite >>> from scipy.stats import norm, genexpon >>> from scipy.special import ndtr >>> import numpy as np
要建立一個從標準常態分佈中取樣的生成器,請執行
>>> class StandardNormal: ... def pdf(self, x): ... return 1/np.sqrt(2*np.pi) * np.exp(-x**2 / 2) ... def cdf(self, x): ... return ndtr(x) ... >>> dist = StandardNormal() >>> urng = np.random.default_rng() >>> rng = NumericalInverseHermite(dist, random_state=urng)
NumericalInverseHermite有一個近似分佈 PPF 的方法。>>> rng = NumericalInverseHermite(dist) >>> p = np.linspace(0.01, 0.99, 99) # percentiles from 1% to 99% >>> np.allclose(rng.ppf(p), norm.ppf(p)) True
根據分佈隨機取樣方法的實作,給定相同的隨機狀態,生成的隨機變數可能幾乎相同。
>>> dist = genexpon(9, 16, 3) >>> rng = NumericalInverseHermite(dist) >>> # `seed` ensures identical random streams are used by each `rvs` method >>> seed = 500072020 >>> rvs1 = dist.rvs(size=100, random_state=np.random.default_rng(seed)) >>> rvs2 = rng.rvs(size=100, random_state=np.random.default_rng(seed)) >>> np.allclose(rvs1, rvs2) True
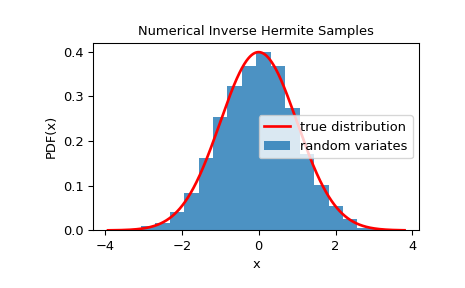
為了檢查隨機變數是否緊密地遵循給定的分佈,我們可以查看其直方圖
>>> import matplotlib.pyplot as plt >>> dist = StandardNormal() >>> rng = NumericalInverseHermite(dist) >>> rvs = rng.rvs(10000) >>> x = np.linspace(rvs.min()-0.1, rvs.max()+0.1, 1000) >>> fx = norm.pdf(x) >>> plt.plot(x, fx, 'r-', lw=2, label='true distribution') >>> plt.hist(rvs, bins=20, density=True, alpha=0.8, label='random variates') >>> plt.xlabel('x') >>> plt.ylabel('PDF(x)') >>> plt.title('Numerical Inverse Hermite Samples') >>> plt.legend() >>> plt.show()
給定 PDF 相對於變數(即 `
x`)的導數,我們可以使用五次 Hermite 插值通過傳遞 order 參數來近似 PPF>>> class StandardNormal: ... def pdf(self, x): ... return 1/np.sqrt(2*np.pi) * np.exp(-x**2 / 2) ... def dpdf(self, x): ... return -1/np.sqrt(2*np.pi) * x * np.exp(-x**2 / 2) ... def cdf(self, x): ... return ndtr(x) ... >>> dist = StandardNormal() >>> urng = np.random.default_rng() >>> rng = NumericalInverseHermite(dist, order=5, random_state=urng)
更高的階數會導致更少的區間數目
>>> rng3 = NumericalInverseHermite(dist, order=3) >>> rng5 = NumericalInverseHermite(dist, order=5) >>> rng3.intervals, rng5.intervals (3000, 522)
u 誤差可以通過調用
u_error方法來估計。它運行一個小的蒙地卡羅模擬來估計 u 誤差。預設情況下,使用 100,000 個樣本。這可以通過傳遞 sample_size 參數來更改>>> rng1 = NumericalInverseHermite(dist, u_resolution=1e-10) >>> rng1.u_error(sample_size=1000000) # uses one million samples UError(max_error=9.53167544892608e-11, mean_absolute_error=2.2450136432146864e-11)
這會返回一個 namedtuple,其中包含最大 u 誤差和平均絕對 u 誤差。
u 誤差可以通過降低 u 解析度(最大允許 u 誤差)來減少
>>> rng2 = NumericalInverseHermite(dist, u_resolution=1e-13) >>> rng2.u_error(sample_size=1000000) UError(max_error=9.32027892364129e-14, mean_absolute_error=1.5194172675685075e-14)
請注意,這會增加設定時間和區間數量的成本。
>>> rng1.intervals 1022 >>> rng2.intervals 5687 >>> from timeit import timeit >>> f = lambda: NumericalInverseHermite(dist, u_resolution=1e-10) >>> timeit(f, number=1) 0.017409582000254886 # may vary >>> f = lambda: NumericalInverseHermite(dist, u_resolution=1e-13) >>> timeit(f, number=1) 0.08671202100003939 # may vary
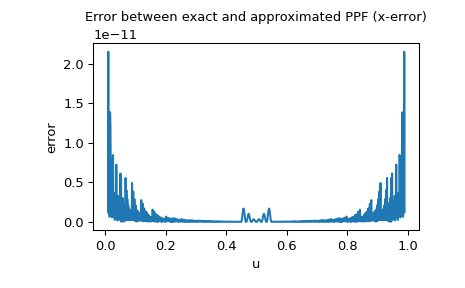
由於常態分佈的 PPF 可以作為特殊函數使用,我們還可以檢查 x 誤差,即近似 PPF 和精確 PPF 之間的差異
>>> import matplotlib.pyplot as plt >>> u = np.linspace(0.01, 0.99, 1000) >>> approxppf = rng.ppf(u) >>> exactppf = norm.ppf(u) >>> error = np.abs(exactppf - approxppf) >>> plt.plot(u, error) >>> plt.xlabel('u') >>> plt.ylabel('error') >>> plt.title('Error between exact and approximated PPF (x-error)') >>> plt.show()
- 屬性:
intervals取得生成器物件中用於 Hermite 插值的節點(設計點)數量。
- midpoint_error
方法
ppf(u)給定分佈的近似 PPF。
qrvs([size, d, qmc_engine])給定 RV 的準隨機變數。
rvs([size, random_state])從分佈中取樣。
set_random_state([random_state])設定底層的均勻分佈隨機數生成器。
u_error([sample_size])使用蒙地卡羅模擬估計近似的 u 誤差。