線性代數 (scipy.linalg)#
當 SciPy 使用最佳化的 ATLAS LAPACK 和 BLAS 庫構建時,它具有非常快速的線性代數能力。 如果您深入研究,所有原始的 LAPACK 和 BLAS 庫都可用於您使用,以獲得更快的速度。 本節將介紹這些例程的一些更易於使用的介面。
所有這些線性代數例程都期望一個可以轉換為 2-D 陣列的物件。 這些例程的輸出也是一個 2-D 陣列。
scipy.linalg vs numpy.linalg#
scipy.linalg 包含 numpy.linalg 中的所有函數,以及 numpy.linalg 中未包含的其他更進階的函數。
使用 scipy.linalg 而不是 numpy.linalg 的另一個優點是,它始終使用 BLAS/LAPACK 支援進行編譯,而 NumPy 則是可選的。 因此,SciPy 版本可能會更快,具體取決於 NumPy 的安裝方式。
因此,除非您不想將 scipy 作為依賴項添加到您的 numpy 程式中,否則請使用 scipy.linalg 而不是 numpy.linalg。
numpy.matrix vs 2-D numpy.ndarray#
代表矩陣的類別和基本操作(例如矩陣乘法和轉置)是 numpy 的一部分。 為了方便起見,我們在此總結了 numpy.matrix 和 numpy.ndarray 之間的差異。
numpy.matrix 是一個矩陣類別,它比 numpy.ndarray 具有更方便的矩陣運算介面。 例如,此類別支援透過分號的類 MATLAB 建立語法,將矩陣乘法作為 * 運算符的預設值,並包含充當逆矩陣和轉置快捷方式的 I 和 T 成員
>>> import numpy as np
>>> A = np.asmatrix('[1 2;3 4]')
>>> A
matrix([[1, 2],
[3, 4]])
>>> A.I
matrix([[-2. , 1. ],
[ 1.5, -0.5]])
>>> b = np.asmatrix('[5 6]')
>>> b
matrix([[5, 6]])
>>> b.T
matrix([[5],
[6]])
>>> A*b.T
matrix([[17],
[39]])
儘管 numpy.matrix 類別很方便,但不建議使用,因為它沒有增加任何無法透過 2-D numpy.ndarray 物件完成的功能,並且可能會導致混淆正在使用的類別。 例如,上面的程式碼可以改寫為
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1,2],[3,4]])
>>> A
array([[1, 2],
[3, 4]])
>>> linalg.inv(A)
array([[-2. , 1. ],
[ 1.5, -0.5]])
>>> b = np.array([[5,6]]) #2D array
>>> b
array([[5, 6]])
>>> b.T
array([[5],
[6]])
>>> A*b #not matrix multiplication!
array([[ 5, 12],
[15, 24]])
>>> A.dot(b.T) #matrix multiplication
array([[17],
[39]])
>>> b = np.array([5,6]) #1D array
>>> b
array([5, 6])
>>> b.T #not matrix transpose!
array([5, 6])
>>> A.dot(b) #does not matter for multiplication
array([17, 39])
scipy.linalg 運算可以同樣應用於 numpy.matrix 或 2D numpy.ndarray 物件。
基本例程#
尋找逆矩陣#
矩陣 \(\mathbf{A}\) 的逆矩陣是矩陣 \(\mathbf{B}\),使得 \(\mathbf{AB}=\mathbf{I}\),其中 \(\mathbf{I}\) 是由主對角線上的 1 組成的單位矩陣。 通常,\(\mathbf{B}\) 表示為 \(\mathbf{B}=\mathbf{A}^{-1}\)。 在 SciPy 中,NumPy 陣列 A 的矩陣逆矩陣是使用 linalg.inv (A) 獲得的,如果 A 是矩陣,則可以使用 A.I。 例如,設
然後
以下範例示範了 SciPy 中的此計算
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1,3,5],[2,5,1],[2,3,8]])
>>> A
array([[1, 3, 5],
[2, 5, 1],
[2, 3, 8]])
>>> linalg.inv(A)
array([[-1.48, 0.36, 0.88],
[ 0.56, 0.08, -0.36],
[ 0.16, -0.12, 0.04]])
>>> A.dot(linalg.inv(A)) #double check
array([[ 1.00000000e+00, -1.11022302e-16, -5.55111512e-17],
[ 3.05311332e-16, 1.00000000e+00, 1.87350135e-16],
[ 2.22044605e-16, -1.11022302e-16, 1.00000000e+00]])
求解線性系統#
使用 scipy 命令 linalg.solve 求解線性方程組非常簡單。 此命令需要輸入矩陣和右側向量。 然後計算解向量。 提供了一個輸入對稱矩陣的選項,這可以在適用的情況下加快處理速度。 例如,假設需要求解以下聯立方程式
我們可以使用矩陣逆矩陣找到解向量
但是,最好使用 linalg.solve 命令,該命令可以更快且數值更穩定。 在這種情況下,它給出的答案與以下範例所示相同
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1, 2], [3, 4]])
>>> A
array([[1, 2],
[3, 4]])
>>> b = np.array([[5], [6]])
>>> b
array([[5],
[6]])
>>> linalg.inv(A).dot(b) # slow
array([[-4. ],
[ 4.5]])
>>> A.dot(linalg.inv(A).dot(b)) - b # check
array([[ 8.88178420e-16],
[ 2.66453526e-15]])
>>> np.linalg.solve(A, b) # fast
array([[-4. ],
[ 4.5]])
>>> A.dot(np.linalg.solve(A, b)) - b # check
array([[ 0.],
[ 0.]])
尋找行列式#
方陣 \(\mathbf{A}\) 的行列式通常表示為 \(\left|\mathbf{A}\right|\),並且是線性代數中常用的量。 假設 \(a_{ij}\) 是矩陣 \(\mathbf{A}\) 的元素,令 \(M_{ij}=\left|\mathbf{A}_{ij}\right|\) 為從 \(\mathbf{A}\) 中移除第 \(i^{\textrm{th}}\) 列和第 \(j^{\textrm{th}}\) 行後剩下的矩陣的行列式。 然後,對於任何列 \(i,\)
這是一種遞迴定義行列式的方法,其中基本情況是接受 \(1\times1\) 矩陣的行列式是唯一的矩陣元素。 在 SciPy 中,可以使用 linalg.det 計算行列式。 例如,行列式
是
在 SciPy 中,此計算方式如本範例所示
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1,2],[3,4]])
>>> A
array([[1, 2],
[3, 4]])
>>> linalg.det(A)
-2.0
計算範數#
矩陣和向量範數也可以使用 SciPy 計算。 使用 linalg.norm 的 order 引數的不同參數,可以使用各種範數定義。 此函數採用 rank-1(向量)或 rank-2(矩陣)陣列和可選的 order 引數(預設值為 2)。 根據這些輸入,計算請求的 order 的向量或矩陣範數。
對於向量 x,order 參數可以是任何實數,包括 inf 或 -inf。 計算出的範數為
對於矩陣 \(\mathbf{A}\),範數的唯一有效值為 \(\pm2,\pm1,\) \(\pm\) inf 和 'fro'(或 'f')。 因此,
其中 \(\sigma_{i}\) 是 \(\mathbf{A}\) 的奇異值。
範例
>>> import numpy as np
>>> from scipy import linalg
>>> A=np.array([[1, 2], [3, 4]])
>>> A
array([[1, 2],
[3, 4]])
>>> linalg.norm(A)
5.4772255750516612
>>> linalg.norm(A, 'fro') # frobenius norm is the default
5.4772255750516612
>>> linalg.norm(A, 1) # L1 norm (max column sum)
6.0
>>> linalg.norm(A, -1)
4.0
>>> linalg.norm(A, np.inf) # L inf norm (max row sum)
7.0
求解線性最小平方問題和偽逆矩陣#
線性最小平方問題出現在應用數學的許多分支中。 在此問題中,尋找一組線性縮放係數,以使模型擬合資料。 特別是,假設資料 \(y_{i}\) 透過一組係數 \(c_{j}\) 和模型函數 \(f_{j}\left(\mathbf{x}_{i}\right)\) 透過模型與資料 \(\mathbf{x}_{i}\) 相關
其中 \(\epsilon_{i}\) 表示資料中的不確定性。 最小平方策略是選擇係數 \(c_{j}\) 以最小化
從理論上講,當
或
其中
當 \(\mathbf{A^{H}A}\) 可逆時,則
其中 \(\mathbf{A}^{\dagger}\) 稱為 \(\mathbf{A}.\) 的偽逆矩陣。 請注意,使用 \(\mathbf{A}\) 的此定義,模型可以寫為
命令 linalg.lstsq 將求解給定 \(\mathbf{A}\) 和 \(\mathbf{y}\) 的 \(\mathbf{c}\) 的線性最小平方問題。 此外,linalg.pinv 將找到給定 \(\mathbf{A}.\) 的 \(\mathbf{A}^{\dagger}\)。
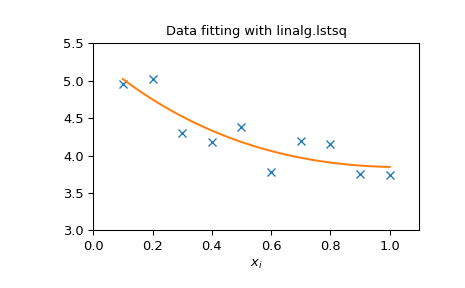
以下範例和圖示示範了使用 linalg.lstsq 和 linalg.pinv 求解資料擬合問題。 下面顯示的資料是使用模型生成的
其中 \(x_{i}=0.1i\) 對於 \(i=1\ldots10\)、\(c_{1}=5\) 和 \(c_{2}=4.\)。 雜訊被添加到 \(y_{i}\),並且使用線性最小平方估計係數 \(c_{1}\) 和 \(c_{2}\)。
>>> import numpy as np
>>> from scipy import linalg
>>> import matplotlib.pyplot as plt
>>> rng = np.random.default_rng()
>>> c1, c2 = 5.0, 2.0
>>> i = np.r_[1:11]
>>> xi = 0.1*i
>>> yi = c1*np.exp(-xi) + c2*xi
>>> zi = yi + 0.05 * np.max(yi) * rng.standard_normal(len(yi))
>>> A = np.c_[np.exp(-xi)[:, np.newaxis], xi[:, np.newaxis]]
>>> c, resid, rank, sigma = linalg.lstsq(A, zi)
>>> xi2 = np.r_[0.1:1.0:100j]
>>> yi2 = c[0]*np.exp(-xi2) + c[1]*xi2
>>> plt.plot(xi,zi,'x',xi2,yi2)
>>> plt.axis([0,1.1,3.0,5.5])
>>> plt.xlabel('$x_i$')
>>> plt.title('Data fitting with linalg.lstsq')
>>> plt.show()
廣義逆矩陣#
廣義逆矩陣是使用命令 linalg.pinv 計算的。 設 \(\mathbf{A}\) 為 \(M\times N\) 矩陣,則如果 \(M>N\),則廣義逆矩陣為
而如果 \(M<N\) 矩陣,則廣義逆矩陣為
在 \(M=N\) 的情況下,則
只要 \(\mathbf{A}\) 是可逆的。
分解#
在許多應用中,使用其他表示形式分解矩陣非常有用。 SciPy 支援多種分解。
特徵值和特徵向量#
特徵值-特徵向量問題是最常用的線性代數運算之一。 在一種流行的形式中,特徵值-特徵向量問題是針對某些方陣 \(\mathbf{A}\) 尋找純量 \(\lambda\) 和相應的向量 \(\mathbf{v}\),使得
對於 \(N\times N\) 矩陣,有 \(N\) 個(不一定相異的)特徵值 — (特徵)多項式的根
特徵向量 \(\mathbf{v}\) 有時也稱為右特徵向量,以區別於滿足以下條件的另一組左特徵向量
或
透過其預設可選引數,命令 linalg.eig 返回 \(\lambda\) 和 \(\mathbf{v}.\)。 但是,它也可以返回 \(\mathbf{v}_{L}\) 和僅返回 \(\lambda\) 本身(linalg.eigvals 也僅返回 \(\lambda\))。
此外,linalg.eig 也可以求解更廣義的特徵值問題
對於方陣 \(\mathbf{A}\) 和 \(\mathbf{B}.\)。 標準特徵值問題是 \(\mathbf{B}=\mathbf{I}.\) 的廣義特徵值問題的範例。 當可以求解廣義特徵值問題時,它會提供 \(\mathbf{A}\) 的分解,如
其中 \(\mathbf{V}\) 是收集到列中的特徵向量,\(\boldsymbol{\Lambda}\) 是特徵值的對角矩陣。
根據定義,特徵向量僅定義到常數比例因子。 在 SciPy 中,特徵向量的縮放因子被選擇為使得 \(\left\Vert \mathbf{v}\right\Vert ^{2}=\sum_{i}v_{i}^{2}=1.\)。
作為範例,考慮尋找矩陣的特徵值和特徵向量
特徵多項式為
此多項式的根是 \(\mathbf{A}\) 的特徵值
可以使用原始方程式找到與每個特徵值對應的特徵向量。 然後可以找到與這些特徵值相關聯的特徵向量。
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1, 2], [3, 4]])
>>> la, v = linalg.eig(A)
>>> l1, l2 = la
>>> print(l1, l2) # eigenvalues
(-0.3722813232690143+0j) (5.372281323269014+0j)
>>> print(v[:, 0]) # first eigenvector
[-0.82456484 0.56576746]
>>> print(v[:, 1]) # second eigenvector
[-0.41597356 -0.90937671]
>>> print(np.sum(abs(v**2), axis=0)) # eigenvectors are unitary
[1. 1.]
>>> v1 = np.array(v[:, 0]).T
>>> print(linalg.norm(A.dot(v1) - l1*v1)) # check the computation
3.23682852457e-16
奇異值分解#
奇異值分解 (SVD) 可以被認為是特徵值問題到非方陣矩陣的擴展。 設 \(\mathbf{A}\) 為 \(M\times N\) 矩陣,其中 \(M\) 和 \(N\) 是任意的。 矩陣 \(\mathbf{A}^{H}\mathbf{A}\) 和 \(\mathbf{A}\mathbf{A}^{H}\) 分別是大小為 \(N\times N\) 和 \(M\times M\) 的方埃爾米特矩陣 [1]。 眾所周知,方埃爾米特矩陣的特徵值是實數且非負數。 此外,\(\mathbf{A}^{H}\mathbf{A}\) 和 \(\mathbf{A}\mathbf{A}^{H}.\) 最多有 \(\min\left(M,N\right)\) 個相同的非零特徵值。 將這些正特徵值定義為 \(\sigma_{i}^{2}.\)。 這些的平方根稱為 \(\mathbf{A}.\) 的奇異值。 \(\mathbf{A}^{H}\mathbf{A}\) 的特徵向量按列收集到 \(N\times N\) 么正矩陣 [2] \(\mathbf{V}\) 中,而 \(\mathbf{A}\mathbf{A}^{H}\) 的特徵向量按列收集在么正矩陣 \(\mathbf{U}\) 中,奇異值收集在 \(M\times N\) 零矩陣 \(\mathbf{\boldsymbol{\Sigma}}\) 中,主對角線條目設定為奇異值。 然後
是 \(\mathbf{A}.\) 的奇異值分解。 每個矩陣都有奇異值分解。 有時,奇異值稱為 \(\mathbf{A}.\) 的譜。 命令 linalg.svd 將返回 \(\mathbf{U}\)、\(\mathbf{V}^{H}\) 和 \(\sigma_{i}\) 作為奇異值陣列。 要獲得矩陣 \(\boldsymbol{\Sigma}\),請使用 linalg.diagsvd。 以下範例說明了 linalg.svd 的用法
>>> import numpy as np
>>> from scipy import linalg
>>> A = np.array([[1,2,3],[4,5,6]])
>>> A
array([[1, 2, 3],
[4, 5, 6]])
>>> M,N = A.shape
>>> U,s,Vh = linalg.svd(A)
>>> Sig = linalg.diagsvd(s,M,N)
>>> U, Vh = U, Vh
>>> U
array([[-0.3863177 , -0.92236578],
[-0.92236578, 0.3863177 ]])
>>> Sig
array([[ 9.508032 , 0. , 0. ],
[ 0. , 0.77286964, 0. ]])
>>> Vh
array([[-0.42866713, -0.56630692, -0.7039467 ],
[ 0.80596391, 0.11238241, -0.58119908],
[ 0.40824829, -0.81649658, 0.40824829]])
>>> U.dot(Sig.dot(Vh)) #check computation
array([[ 1., 2., 3.],
[ 4., 5., 6.]])
LU 分解#
LU 分解找到 \(M\times N\) 矩陣 \(\mathbf{A}\) 的表示形式,如
其中 \(\mathbf{P}\) 是 \(M\times M\) 置換矩陣(單位矩陣的列的置換),\(\mathbf{L}\) 在 \(M\times K\) 下三角或梯形矩陣中(\(K=\min\left(M,N\right)\)),具有單位對角線,\(\mathbf{U}\) 是上三角或梯形矩陣。 此分解的 SciPy 命令是 linalg.lu。
這種分解通常適用於求解許多聯立方程式,其中左側不變,但右側會變。 例如,假設我們將求解
對於許多不同的 \(\mathbf{b}_{i}\)。 LU 分解允許將其寫為
因為 \(\mathbf{L}\) 是下三角矩陣,所以可以使用前向和後向替換非常快速地求解 \(\mathbf{U}\mathbf{x}_{i}\) 的方程式,最後求解 \(\mathbf{x}_{i}\)。 花費初始時間分解 \(\mathbf{A}\) 可以在未來非常快速地求解類似的方程組。 如果執行 LU 分解的目的是為了求解線性系統,則應使用命令 linalg.lu_factor,然後重複應用命令 linalg.lu_solve,以針對每個新的右側求解系統。
Cholesky 分解#
Cholesky 分解是 LU 分解的一種特殊情況,適用於埃爾米特正定矩陣。 當 \(\mathbf{A}=\mathbf{A}^{H}\) 且對於所有 \(\mathbf{x}\),\(\mathbf{x}^{H}\mathbf{Ax}\geq0\) 時,可以找到 \(\mathbf{A}\) 的分解,使得
其中 \(\mathbf{L}\) 是下三角矩陣,\(\mathbf{U}\) 是上三角矩陣。 請注意,\(\mathbf{L}=\mathbf{U}^{H}.\)。 命令 linalg.cholesky 計算 Cholesky 因式分解。 為了使用 Cholesky 因式分解求解方程組,還有 linalg.cho_factor 和 linalg.cho_solve 例程,它們的工作方式與 LU 分解對應項類似。
QR 分解#
QR 分解(有時稱為極分解)適用於任何 \(M\times N\) 陣列,並找到 \(M\times M\) 么正矩陣 \(\mathbf{Q}\) 和 \(M\times N\) 上梯形矩陣 \(\mathbf{R}\),使得
請注意,如果已知 \(\mathbf{A}\) 的 SVD,則可以找到 QR 分解。
表示 \(\mathbf{Q}=\mathbf{U}\) 和 \(\mathbf{R}=\boldsymbol{\Sigma}\mathbf{V}^{H}.\)。 但是請注意,在 SciPy 中,使用獨立的演算法來尋找 QR 和 SVD 分解。 QR 分解的命令是 linalg.qr。
Schur 分解#
對於方陣 \(N\times N\) 矩陣 \(\mathbf{A}\),Schur 分解找到(不一定唯一的)矩陣 \(\mathbf{T}\) 和 \(\mathbf{Z}\),使得
其中 \(\mathbf{Z}\) 是么正矩陣,\(\mathbf{T}\) 是上三角矩陣或擬上三角矩陣,具體取決於是否請求實 Schur 形式或複 Schur 形式。 對於實 Schur 形式,當 \(\mathbf{A}\) 是實值時,\(\mathbf{T}\) 和 \(\mathbf{Z}\) 都是實值。 當 \(\mathbf{A}\) 是實值矩陣時,實 Schur 形式僅是擬上三角矩陣,因為 \(2\times2\) 方塊從主對角線突出,對應於任何複值特徵值。 命令 linalg.schur 尋找 Schur 分解,而命令 linalg.rsf2csf 將 \(\mathbf{T}\) 和 \(\mathbf{Z}\) 從實 Schur 形式轉換為複 Schur 形式。 Schur 形式在計算矩陣函數時特別有用。
以下範例說明了 Schur 分解
>>> from scipy import linalg
>>> A = np.asmatrix('[1 3 2; 1 4 5; 2 3 6]')
>>> T, Z = linalg.schur(A)
>>> T1, Z1 = linalg.schur(A, 'complex')
>>> T2, Z2 = linalg.rsf2csf(T, Z)
>>> T
array([[ 9.90012467, 1.78947961, -0.65498528],
[ 0. , 0.54993766, -1.57754789],
[ 0. , 0.51260928, 0.54993766]])
>>> T2
array([[ 9.90012467+0.00000000e+00j, -0.32436598+1.55463542e+00j,
-0.88619748+5.69027615e-01j],
[ 0. +0.00000000e+00j, 0.54993766+8.99258408e-01j,
1.06493862+3.05311332e-16j],
[ 0. +0.00000000e+00j, 0. +0.00000000e+00j,
0.54993766-8.99258408e-01j]])
>>> abs(T1 - T2) # different
array([[ 1.06604538e-14, 2.06969555e+00, 1.69375747e+00], # may vary
[ 0.00000000e+00, 1.33688556e-15, 4.74146496e-01],
[ 0.00000000e+00, 0.00000000e+00, 1.13220977e-15]])
>>> abs(Z1 - Z2) # different
array([[ 0.06833781, 0.88091091, 0.79568503], # may vary
[ 0.11857169, 0.44491892, 0.99594171],
[ 0.12624999, 0.60264117, 0.77257633]])
>>> T, Z, T1, Z1, T2, Z2 = map(np.asmatrix,(T,Z,T1,Z1,T2,Z2))
>>> abs(A - Z*T*Z.H) # same
matrix([[ 5.55111512e-16, 1.77635684e-15, 2.22044605e-15],
[ 0.00000000e+00, 3.99680289e-15, 8.88178420e-16],
[ 1.11022302e-15, 4.44089210e-16, 3.55271368e-15]])
>>> abs(A - Z1*T1*Z1.H) # same
matrix([[ 4.26993904e-15, 6.21793362e-15, 8.00007092e-15],
[ 5.77945386e-15, 6.21798014e-15, 1.06653681e-14],
[ 7.16681444e-15, 8.90271058e-15, 1.77635764e-14]])
>>> abs(A - Z2*T2*Z2.H) # same
matrix([[ 6.02594127e-16, 1.77648931e-15, 2.22506907e-15],
[ 2.46275555e-16, 3.99684548e-15, 8.91642616e-16],
[ 8.88225111e-16, 8.88312432e-16, 4.44104848e-15]])
插值分解#
scipy.linalg.interpolative 包含用於計算矩陣的插值分解 (ID) 的常式。對於秩為 \(k \leq \min \{ m, n \}\) 的矩陣 \(A \in \mathbb{C}^{m \times n}\),這是一個因式分解
其中 \(\Pi = [\Pi_{1}, \Pi_{2}]\) 是一個置換矩陣,其中 \(\Pi_{1} \in \{ 0, 1 \}^{n \times k}\),即 \(A \Pi_{2} = A \Pi_{1} T\)。這可以等價地寫為 \(A = BP\),其中 \(B = A \Pi_{1}\) 和 \(P = [I, T] \Pi^{\mathsf{T}}\) 分別是骨架矩陣和插值矩陣。
另請參閱
scipy.linalg.interpolative — 以獲得更多資訊。
矩陣函數#
考慮函數 \(f\left(x\right)\) 及其泰勒級數展開式
矩陣函數可以使用方陣 \(\mathbf{A}\) 的泰勒級數定義為
注意
雖然這可以作為矩陣函數的有用表示,但它很少是計算矩陣函數的最佳方法。特別是,如果矩陣不可對角化,則結果可能不準確。
指數和對數函數#
矩陣指數是最常見的矩陣函數之一。實作矩陣指數的首選方法是使用縮放和 Padé 逼近 \(e^{x}\)。此演算法實作為 linalg.expm。
矩陣指數的逆函數是矩陣對數,定義為矩陣指數的逆函數
可以使用 linalg.logm 獲得矩陣對數。
三角函數#
三角函數 \(\sin\)、\(\cos\) 和 \(\tan\) 在 linalg.sinm、linalg.cosm 和 linalg.tanm 中針對矩陣實作。矩陣正弦和餘弦可以使用尤拉公式定義為
正切是
因此,矩陣正切定義為
雙曲三角函數#
雙曲三角函數 \(\sinh\)、\(\cosh\) 和 \(\tanh\) 也可以使用熟悉的定義針對矩陣定義
這些矩陣函數可以使用 linalg.sinhm、linalg.coshm 和 linalg.tanhm 找到。
任意函數#
最後,任何接受一個複數並傳回複數的任意函數都可以使用命令 linalg.funm 作為矩陣函數呼叫。此命令接受矩陣和任意 Python 函數。然後,它實作 Golub 和 Van Loan 的著作「矩陣計算」中的演算法,以使用 Schur 分解計算應用於矩陣的函數。請注意,函數需要接受複數作為輸入,才能使用此演算法。例如,以下程式碼計算應用於矩陣的零階貝索函數。
>>> from scipy import special, linalg
>>> rng = np.random.default_rng()
>>> A = rng.random((3, 3))
>>> B = linalg.funm(A, lambda x: special.jv(0, x))
>>> A
array([[0.06369197, 0.90647174, 0.98024544],
[0.68752227, 0.5604377 , 0.49142032],
[0.86754578, 0.9746787 , 0.37932682]])
>>> B
array([[ 0.6929219 , -0.29728805, -0.15930896],
[-0.16226043, 0.71967826, -0.22709386],
[-0.19945564, -0.33379957, 0.70259022]])
>>> linalg.eigvals(A)
array([ 1.94835336+0.j, -0.72219681+0.j, -0.22270006+0.j])
>>> special.jv(0, linalg.eigvals(A))
array([0.25375345+0.j, 0.87379738+0.j, 0.98763955+0.j])
>>> linalg.eigvals(B)
array([0.25375345+0.j, 0.87379738+0.j, 0.98763955+0.j])
請注意,由於矩陣解析函數的定義方式,貝索函數已作用於矩陣特徵值。
特殊矩陣#
SciPy 和 NumPy 提供了幾個函數,用於建立工程和科學中常用的特殊矩陣。
類型 |
函數 |
描述 |
|---|---|---|
區塊對角 |
從提供的陣列建立區塊對角矩陣。 |
|
循環 |
建立循環矩陣。 |
|
伴隨 |
建立伴隨矩陣。 |
|
卷積 |
建立卷積矩陣。 |
|
離散傅立葉 |
建立離散傅立葉轉換矩陣。 |
|
Fiedler |
建立對稱 Fiedler 矩陣。 |
|
Fiedler 伴隨 |
建立 Fiedler 伴隨矩陣。 |
|
Hadamard |
建立 Hadamard 矩陣。 |
|
Hankel |
建立 Hankel 矩陣。 |
|
Helmert |
建立 Helmert 矩陣。 |
|
Hilbert |
建立 Hilbert 矩陣。 |
|
反 Hilbert |
建立 Hilbert 矩陣的反矩陣。 |
|
Leslie |
建立 Leslie 矩陣。 |
|
Pascal |
建立 Pascal 矩陣。 |
|
反 Pascal |
建立 Pascal 矩陣的反矩陣。 |
|
Toeplitz |
建立 Toeplitz 矩陣。 |
|
Van der Monde |
建立 Van der Monde 矩陣。 |
有關這些函數的使用範例,請參閱它們各自的 docstring。