多維影像處理 (scipy.ndimage)#
簡介#
影像處理與分析通常被視為對二維數值陣列的操作。然而,在許多領域中,必須分析更高維度的影像。醫學影像和生物影像就是很好的例子。numpy 非常適合這類應用,因為它本身就具有多維度特性。scipy.ndimage 套件提供許多通用的影像處理與分析函數,這些函數被設計用於操作任意維度的陣列。該套件目前包含:線性與非線性濾波、二元形態學、B-spline 內插和物件測量的函數。
濾波函數#
本節描述的函數都對輸入陣列執行某種類型的空間濾波:輸出中的元素是相應輸入元素鄰域中值的函數。我們將元素的這種鄰域稱為濾波器核心,它通常是矩形的形狀,但也可能具有任意的足跡。以下描述的許多函數都允許您透過傳遞一個遮罩到 footprint 參數來定義核心的足跡。例如,一個十字形核心可以定義如下
>>> footprint = np.array([[0, 1, 0], [1, 1, 1], [0, 1, 0]])
>>> footprint
array([[0, 1, 0],
[1, 1, 1],
[0, 1, 0]])
通常,核心的原點位於中心,該中心透過將核心形狀的維度除以二來計算。例如,長度為三的一維核心的原點位於第二個元素。例如,考慮一個一維陣列與由一組成的長度為 3 的濾波器的相關性
>>> from scipy.ndimage import correlate1d
>>> a = [0, 0, 0, 1, 0, 0, 0]
>>> correlate1d(a, [1, 1, 1])
array([0, 0, 1, 1, 1, 0, 0])
有時,選擇不同的核心原點會很方便。因此,大多數函數都支援 origin 參數,該參數給出濾波器相對於其中心的原點。例如
>>> a = [0, 0, 0, 1, 0, 0, 0]
>>> correlate1d(a, [1, 1, 1], origin = -1)
array([0, 1, 1, 1, 0, 0, 0])
效果是結果向左移動。這個功能不會經常需要,但它可能很有用,特別是對於具有偶數大小的濾波器。一個很好的例子是計算向後和向前差分
>>> a = [0, 0, 1, 1, 1, 0, 0]
>>> correlate1d(a, [-1, 1]) # backward difference
array([ 0, 0, 1, 0, 0, -1, 0])
>>> correlate1d(a, [-1, 1], origin = -1) # forward difference
array([ 0, 1, 0, 0, -1, 0, 0])
我們也可以如下計算向前差分
>>> correlate1d(a, [0, -1, 1])
array([ 0, 1, 0, 0, -1, 0, 0])
然而,使用 origin 參數而不是更大的核心更有效率。對於多維核心,origin 可以是一個數字,在這種情況下,原點被假定在所有軸上都相等,或者是一個給出每個軸上原點的序列。
由於輸出元素是輸入元素鄰域中元素的函數,因此需要透過提供邊界外的值來適當地處理陣列的邊界。這是透過假設陣列根據某些邊界條件擴展到其邊界之外來完成的。在下面描述的函數中,可以使用 mode 參數選擇邊界條件,mode 參數必須是一個字串,其中包含邊界條件的名稱。目前支援以下邊界條件
模式
描述
範例
“最近”
使用邊界上的值
[1 2 3]->[1 1 2 3 3]
“環繞”
週期性地複製陣列
[1 2 3]->[3 1 2 3 1]
“反射”
在邊界反射陣列
[1 2 3]->[1 1 2 3 3]
“鏡射”
在邊界鏡射陣列
[1 2 3]->[2 1 2 3 2]
“常數”
使用常數值,預設值為 0.0
[1 2 3]->[0 1 2 3 0]
為了與內插常式保持一致,也支援以下同義詞
模式
描述
“網格-常數”
等同於 “常數”*
“網格-鏡射”
等同於 “反射”
“網格-環繞”
等同於 “環繞”
* “網格-常數” 和 “常數” 對於濾波操作是等效的,但在內插函數中具有不同的行為。為了 API 的一致性,濾波函數接受任一名稱。
“常數” 模式很特殊,因為它需要一個額外的參數來指定應使用的常數值。
請注意,模式鏡射和反射僅在邊界上的樣本在反射時是否重複方面有所不同。對於模式鏡射,對稱點正好位於最後一個樣本處,因此該值不會重複。這種模式也稱為全樣本對稱,因為對稱點落在最後一個樣本上。同樣地,反射通常被稱為半樣本對稱,因為對稱點位於陣列邊界之外半個樣本處。
注意
實作此類邊界條件最簡單的方法是將資料複製到更大的陣列,並根據邊界條件擴展邊界上的資料。對於大型陣列和大型濾波器核心,這將非常消耗記憶體,因此,下面描述的函數使用了一種不同的方法,該方法不需要分配大型的暫存緩衝區。
相關與卷積#
correlate1d函數沿著給定的軸計算一維相關性。沿著給定軸的陣列線與給定的 weights 相關。weights 參數必須是一維數字序列。函數
correlate實作輸入陣列與給定核心的多維相關性。convolve1d函數沿著給定的軸計算一維卷積。沿著給定軸的陣列線與給定的 weights 進行卷積。weights 參數必須是一維數字序列。函數
convolve實作輸入陣列與給定核心的多維卷積。注意
卷積本質上是在鏡射核心後的相關性。因此,origin 參數的行為與相關性的情況不同:結果朝相反方向移動。
平滑濾波器#
gaussian_filter1d函數實作一維高斯濾波器。高斯濾波器的標準差透過參數 sigma 傳遞。設定 order = 0 對應於與高斯核心進行卷積。order 為 1、2 或 3 對應於與高斯的一階、二階或三階導數進行卷積。更高階的導數未實作。gaussian_filter函數實作多維高斯濾波器。沿著每個軸的高斯濾波器的標準差透過參數 sigma 作為序列或數字傳遞。如果 sigma 不是序列而是一個數字,則濾波器的標準差在所有方向上都相等。可以為每個軸分別指定濾波器的階數。階數為 0 對應於與高斯核心進行卷積。階數為 1、2 或 3 對應於與高斯的一階、二階或三階導數進行卷積。更高階的導數未實作。order 參數必須是一個數字(用於指定所有軸的相同階數)或一個數字序列(用於指定每個軸的不同階數)。下面的範例顯示了應用於具有不同 sigma 值的測試資料的濾波器。order 參數保持為 0。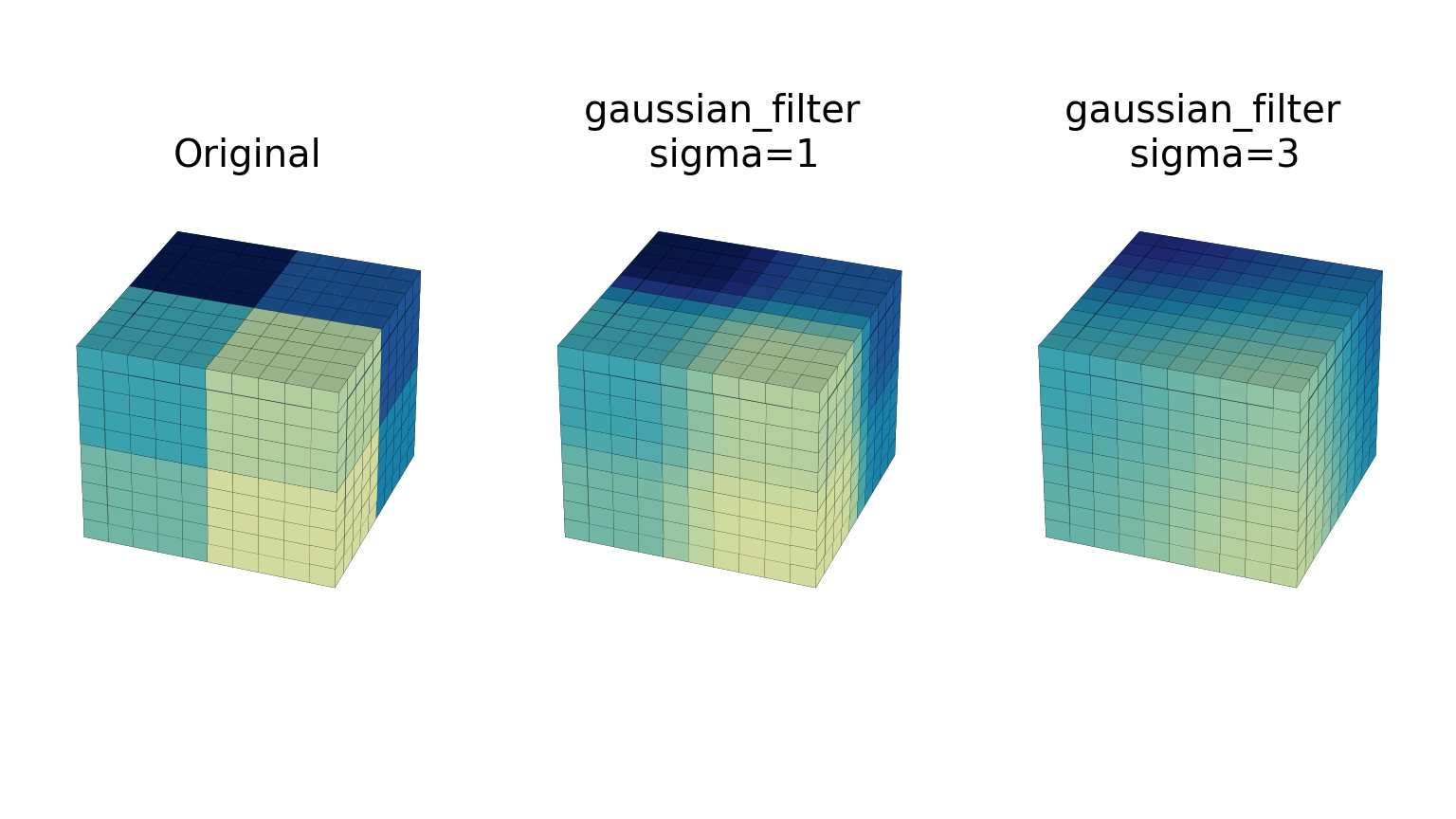
注意
多維濾波器實作為一維高斯濾波器的序列。中間陣列以與輸出相同的資料類型儲存。因此,對於精度較低的輸出類型,結果可能不精確,因為中間結果可能以不夠的精度儲存。這可以透過指定更精確的輸出類型來避免。
uniform_filter1d函數沿著給定的軸計算給定 size 的一維均勻濾波器。uniform_filter實作多維均勻濾波器。均勻濾波器的大小透過 size 參數作為整數序列給出每個軸的大小。如果 size 不是序列,而是一個數字,則假定所有軸的大小都相等。注意
多維濾波器實作為一維均勻濾波器的序列。中間陣列以與輸出相同的資料類型儲存。因此,對於精度較低的輸出類型,結果可能不精確,因為中間結果可能以不夠的精度儲存。這可以透過指定更精確的輸出類型來避免。
基於順序統計的濾波器#
minimum_filter1d函數沿著給定的軸計算給定 size 的一維最小值濾波器。maximum_filter1d函數沿著給定的軸計算給定 size 的一維最大值濾波器。minimum_filter函數計算多維最小值濾波器。必須提供矩形核心的大小或核心的足跡。size 參數(如果提供)必須是大小序列或單個數字,在這種情況下,假定濾波器的大小在每個軸上都相等。footprint(如果提供)必須是一個陣列,透過其非零元素定義核心的形狀。maximum_filter函數計算多維最大值濾波器。必須提供矩形核心的大小或核心的足跡。size 參數(如果提供)必須是大小序列或單個數字,在這種情況下,假定濾波器的大小在每個軸上都相等。footprint(如果提供)必須是一個陣列,透過其非零元素定義核心的形狀。rank_filter函數計算多維秩濾波器。rank 可能小於零,即 rank = -1 表示最大的元素。必須提供矩形核心的大小或核心的足跡。size 參數(如果提供)必須是大小序列或單個數字,在這種情況下,假定濾波器的大小在每個軸上都相等。footprint(如果提供)必須是一個陣列,透過其非零元素定義核心的形狀。percentile_filter函數計算多維百分位數濾波器。percentile 可能小於零,即 percentile = -20 等於 percentile = 80。必須提供矩形核心的大小或核心的足跡。size 參數(如果提供)必須是大小序列或單個數字,在這種情況下,假定濾波器的大小在每個軸上都相等。footprint(如果提供)必須是一個陣列,透過其非零元素定義核心的形狀。median_filter函數計算多維中值濾波器。必須提供矩形核心的大小或核心的足跡。size 參數(如果提供)必須是大小序列或單個數字,在這種情況下,假定濾波器的大小在每個軸上都相等。footprint(如果提供)必須是一個陣列,透過其非零元素定義核心的形狀。
導數#
導數濾波器可以透過幾種方式建構。gaussian_filter1d 函數(在 平滑濾波器 中描述)可用於使用 order 參數計算沿給定軸的導數。其他導數濾波器包括 Prewitt 和 Sobel 濾波器
拉普拉斯濾波器透過所有軸的二階導數之和計算。因此,可以使用不同的二階導數函數來建構不同的拉普拉斯濾波器。因此,我們提供一個通用函數,該函數接受函數參數以計算沿給定方向的二階導數。
generic_laplace函數使用透過derivative2傳遞的函數計算拉普拉斯濾波器,以計算二階導數。函數derivative2應具有以下簽名derivative2(input, axis, output, mode, cval, *extra_arguments, **extra_keywords)
它應該計算沿維度 axis 的二階導數。如果 output 不是
None,它應該使用它作為輸出並傳回None,否則它應該傳回結果。mode, cval 具有通常的含義。extra_arguments 和 extra_keywords 參數可用於傳遞額外參數的元組和具名參數的字典,這些參數在每次呼叫時都會傳遞給
derivative2。例如
>>> def d2(input, axis, output, mode, cval): ... return correlate1d(input, [1, -2, 1], axis, output, mode, cval, 0) ... >>> a = np.zeros((5, 5)) >>> a[2, 2] = 1 >>> from scipy.ndimage import generic_laplace >>> generic_laplace(a, d2) array([[ 0., 0., 0., 0., 0.], [ 0., 0., 1., 0., 0.], [ 0., 1., -4., 1., 0.], [ 0., 0., 1., 0., 0.], [ 0., 0., 0., 0., 0.]])
為了示範 extra_arguments 參數的使用,我們可以執行
>>> def d2(input, axis, output, mode, cval, weights): ... return correlate1d(input, weights, axis, output, mode, cval, 0,) ... >>> a = np.zeros((5, 5)) >>> a[2, 2] = 1 >>> generic_laplace(a, d2, extra_arguments = ([1, -2, 1],)) array([[ 0., 0., 0., 0., 0.], [ 0., 0., 1., 0., 0.], [ 0., 1., -4., 1., 0.], [ 0., 0., 1., 0., 0.], [ 0., 0., 0., 0., 0.]])
或
>>> generic_laplace(a, d2, extra_keywords = {'weights': [1, -2, 1]}) array([[ 0., 0., 0., 0., 0.], [ 0., 0., 1., 0., 0.], [ 0., 1., -4., 1., 0.], [ 0., 0., 1., 0., 0.], [ 0., 0., 0., 0., 0.]])
以下兩個函數是透過為二階導數函數提供適當的函數,使用 generic_laplace 實作的
laplace函數使用離散微分計算拉普拉斯算子以獲得二階導數(即,與[1, -2, 1]進行卷積)。gaussian_laplace函數使用gaussian_filter計算拉普拉斯濾波器,以計算二階導數。沿著每個軸的高斯濾波器的標準差透過參數 sigma 作為序列或數字傳遞。如果 sigma 不是序列而是一個數字,則濾波器的標準差在所有方向上都相等。
梯度幅度定義為所有方向梯度平方和的平方根。與通用拉普拉斯函數類似,有一個 generic_gradient_magnitude 函數,用於計算陣列的梯度幅度。
generic_gradient_magnitude函數使用透過derivative傳遞的函數計算梯度幅度,以計算一階導數。函數derivative應具有以下簽名derivative(input, axis, output, mode, cval, *extra_arguments, **extra_keywords)
它應該計算沿維度 axis 的導數。如果 output 不是
None,它應該使用它作為輸出並傳回None,否則它應該傳回結果。mode, cval 具有通常的含義。extra_arguments 和 extra_keywords 參數可用於傳遞額外參數的元組和具名參數的字典,這些參數在每次呼叫時都會傳遞給 derivative。
例如,
sobel函數符合所需的簽名>>> a = np.zeros((5, 5)) >>> a[2, 2] = 1 >>> from scipy.ndimage import sobel, generic_gradient_magnitude >>> generic_gradient_magnitude(a, sobel) array([[ 0. , 0. , 0. , 0. , 0. ], [ 0. , 1.41421356, 2. , 1.41421356, 0. ], [ 0. , 2. , 0. , 2. , 0. ], [ 0. , 1.41421356, 2. , 1.41421356, 0. ], [ 0. , 0. , 0. , 0. , 0. ]])
請參閱
generic_laplace的文件,以取得使用 extra_arguments 和 extra_keywords 參數的範例。
sobel 和 prewitt 函數符合所需的簽名,因此可以直接與 generic_gradient_magnitude 一起使用。
gaussian_gradient_magnitude函數使用gaussian_filter計算梯度幅度,以計算一階導數。沿著每個軸的高斯濾波器的標準差透過參數 sigma 作為序列或數字傳遞。如果 sigma 不是序列而是一個數字,則濾波器的標準差在所有方向上都相等。
通用濾波函數#
為了實作濾波函數,可以使用通用函數,這些函數接受實作濾波操作的可呼叫物件。輸入和輸出陣列的迭代由這些通用函數處理,以及諸如邊界條件的實作等細節。只需要提供一個實作執行實際濾波工作的回呼函數的可呼叫物件。回呼函數也可以用 C 語言編寫,並使用 PyCapsule 傳遞(請參閱 在 C 中擴展 scipy.ndimage 以取得更多資訊)。
generic_filter1d函數實作通用一維濾波函數,其中實際的濾波操作必須作為 python 函數(或其他可呼叫物件)提供。generic_filter1d函數迭代陣列的線,並在每條線上呼叫function。傳遞給function的參數是numpy.float64類型的一維陣列。第一個包含目前線的值。它根據 filter_size 和 origin 參數在開頭和結尾處擴展。第二個陣列應原地修改以提供該行的輸出值。例如,考慮沿一個維度的相關性>>> a = np.arange(12).reshape(3,4) >>> correlate1d(a, [1, 2, 3]) array([[ 3, 8, 14, 17], [27, 32, 38, 41], [51, 56, 62, 65]])
相同的操作可以使用
generic_filter1d實作,如下所示>>> def fnc(iline, oline): ... oline[...] = iline[:-2] + 2 * iline[1:-1] + 3 * iline[2:] ... >>> from scipy.ndimage import generic_filter1d >>> generic_filter1d(a, fnc, 3) array([[ 3, 8, 14, 17], [27, 32, 38, 41], [51, 56, 62, 65]])
在這裡,核心的原點(預設情況下)被假定為位於長度為 3 的濾波器的中間。因此,在呼叫函數之前,每個輸入行都在開頭和結尾處擴展了一個值。
或者,可以定義額外參數並將其傳遞給濾波函數。extra_arguments 和 extra_keywords 參數可用於傳遞額外參數的元組和/或具名參數的字典,這些參數在每次呼叫時都會傳遞給 derivative。例如,我們可以將濾波器的參數作為參數傳遞
>>> def fnc(iline, oline, a, b): ... oline[...] = iline[:-2] + a * iline[1:-1] + b * iline[2:] ... >>> generic_filter1d(a, fnc, 3, extra_arguments = (2, 3)) array([[ 3, 8, 14, 17], [27, 32, 38, 41], [51, 56, 62, 65]])
或
>>> generic_filter1d(a, fnc, 3, extra_keywords = {'a':2, 'b':3}) array([[ 3, 8, 14, 17], [27, 32, 38, 41], [51, 56, 62, 65]])
generic_filter函數實作通用濾波函數,其中實際的濾波操作必須作為 python 函數(或其他可呼叫物件)提供。generic_filter函數迭代陣列,並在每個元素處呼叫function。function的參數是一個numpy.float64類型的一維陣列,其中包含目前元素周圍且位於濾波器足跡內的值。該函數應傳回一個可以轉換為雙精度數字的單一值。例如,考慮一個相關性>>> a = np.arange(12).reshape(3,4) >>> correlate(a, [[1, 0], [0, 3]]) array([[ 0, 3, 7, 11], [12, 15, 19, 23], [28, 31, 35, 39]])
相同的操作可以使用 generic_filter 實作,如下所示
>>> def fnc(buffer): ... return (buffer * np.array([1, 3])).sum() ... >>> from scipy.ndimage import generic_filter >>> generic_filter(a, fnc, footprint = [[1, 0], [0, 1]]) array([[ 0, 3, 7, 11], [12, 15, 19, 23], [28, 31, 35, 39]])
在這裡,指定了一個僅包含兩個元素的核心足跡。因此,濾波函數接收一個長度等於二的緩衝區,該緩衝區與適當的權重相乘,並將結果相加。
在呼叫
generic_filter時,必須提供矩形核心的大小或核心的足跡。size 參數(如果提供)必須是大小序列或單個數字,在這種情況下,假定濾波器的大小在每個軸上都相等。footprint(如果提供)必須是一個陣列,透過其非零元素定義核心的形狀。或者,可以定義額外參數並將其傳遞給濾波函數。extra_arguments 和 extra_keywords 參數可用於傳遞額外參數的元組和/或具名參數的字典,這些參數在每次呼叫時都會傳遞給 derivative。例如,我們可以將濾波器的參數作為參數傳遞
>>> def fnc(buffer, weights): ... weights = np.asarray(weights) ... return (buffer * weights).sum() ... >>> generic_filter(a, fnc, footprint = [[1, 0], [0, 1]], extra_arguments = ([1, 3],)) array([[ 0, 3, 7, 11], [12, 15, 19, 23], [28, 31, 35, 39]])
或
>>> generic_filter(a, fnc, footprint = [[1, 0], [0, 1]], extra_keywords= {'weights': [1, 3]}) array([[ 0, 3, 7, 11], [12, 15, 19, 23], [28, 31, 35, 39]])
這些函數從最後一個軸開始迭代線或元素,也就是說,最後一個索引變化最快。保證這種迭代順序適用於根據空間位置調整濾波器很重要的情況。以下是使用一個類別的範例,該類別實作濾波器並在迭代時追蹤目前的座標。它執行與上述 generic_filter 相同的濾波操作,但另外列印目前的座標
>>> a = np.arange(12).reshape(3,4)
>>>
>>> class fnc_class:
... def __init__(self, shape):
... # store the shape:
... self.shape = shape
... # initialize the coordinates:
... self.coordinates = [0] * len(shape)
...
... def filter(self, buffer):
... result = (buffer * np.array([1, 3])).sum()
... print(self.coordinates)
... # calculate the next coordinates:
... axes = list(range(len(self.shape)))
... axes.reverse()
... for jj in axes:
... if self.coordinates[jj] < self.shape[jj] - 1:
... self.coordinates[jj] += 1
... break
... else:
... self.coordinates[jj] = 0
... return result
...
>>> fnc = fnc_class(shape = (3,4))
>>> generic_filter(a, fnc.filter, footprint = [[1, 0], [0, 1]])
[0, 0]
[0, 1]
[0, 2]
[0, 3]
[1, 0]
[1, 1]
[1, 2]
[1, 3]
[2, 0]
[2, 1]
[2, 2]
[2, 3]
array([[ 0, 3, 7, 11],
[12, 15, 19, 23],
[28, 31, 35, 39]])
對於 generic_filter1d 函數,相同的方法有效,只是此函數不迭代正在濾波的軸。然後 generic_filter1d 的範例變成這樣
>>> a = np.arange(12).reshape(3,4)
>>>
>>> class fnc1d_class:
... def __init__(self, shape, axis = -1):
... # store the filter axis:
... self.axis = axis
... # store the shape:
... self.shape = shape
... # initialize the coordinates:
... self.coordinates = [0] * len(shape)
...
... def filter(self, iline, oline):
... oline[...] = iline[:-2] + 2 * iline[1:-1] + 3 * iline[2:]
... print(self.coordinates)
... # calculate the next coordinates:
... axes = list(range(len(self.shape)))
... # skip the filter axis:
... del axes[self.axis]
... axes.reverse()
... for jj in axes:
... if self.coordinates[jj] < self.shape[jj] - 1:
... self.coordinates[jj] += 1
... break
... else:
... self.coordinates[jj] = 0
...
>>> fnc = fnc1d_class(shape = (3,4))
>>> generic_filter1d(a, fnc.filter, 3)
[0, 0]
[1, 0]
[2, 0]
array([[ 3, 8, 14, 17],
[27, 32, 38, 41],
[51, 56, 62, 65]])
傅立葉域濾波器#
本節描述的功能在傅立葉域中執行濾波操作。因此,此類函數的輸入陣列應與反傅立葉轉換函數相容,例如來自 numpy.fft 模組的函數。因此,我們必須處理可能是實數或複數傅立葉轉換結果的陣列。在實數傅立葉轉換的情況下,僅儲存對稱複數轉換的一半。此外,需要知道軸的長度,該軸已由實數 fft 轉換。此處描述的函數提供了一個參數 n,在實數轉換的情況下,該參數必須等於轉換前實數轉換軸的長度。如果此參數小於零,則假定輸入陣列是複數傅立葉轉換的結果。參數 axis 可用於指示沿哪個軸執行了實數轉換。
fourier_shift函數將輸入陣列與給定位移的位移操作的多維傅立葉轉換相乘。shift 參數是每個維度的位移序列,或是所有維度的單一值。fourier_gaussian函數將輸入陣列與具有給定標準差 sigma 的高斯濾波器的多維傅立葉轉換相乘。sigma 參數是每個維度的值序列,或是所有維度的單一值。fourier_uniform函數將輸入陣列與具有給定大小 size 的均勻濾波器的多維傅立葉轉換相乘。size 參數是每個維度的值序列,或是所有維度的單一值。fourier_ellipsoid函數將輸入陣列與具有給定大小 size 的橢圓形濾波器的多維傅立葉轉換相乘。size 參數是每個維度的值序列,或是所有維度的單一值。此函數僅針對維度 1、2 和 3 實作。
內插函數#
本節描述了各種基於 B-spline 理論的內插函數。關於 B-spline 的良好介紹可以在 [1] 中找到,而 [5] 中給出了影像內插的詳細演算法。
樣條預先濾波器#
使用大於 1 階的樣條進行內插需要預先濾波步驟。內插函數 節中描述的內插函數透過呼叫 spline_filter 來應用預先濾波,但可以透過將 prefilter 關鍵字設定為 False 來指示它們不要執行此操作。如果對同一個陣列執行多個內插操作,這會很有用。在這種情況下,僅執行一次預先濾波並使用預先濾波的陣列作為內插函數的輸入會更有效率。以下兩個函數實作了預先濾波
spline_filter1d函數沿給定軸計算 1-D 樣條濾波器。可以選擇性地提供輸出陣列。樣條的階數必須大於 1 且小於 6。spline_filter函數計算多維樣條濾波器。注意
多維濾波器實作為 1-D 樣條濾波器序列。中間陣列以與輸出相同的資料類型儲存。因此,如果請求有限精度的輸出,則結果可能不精確,因為中間結果可能以不夠的精度儲存。可以透過指定高精度的輸出類型來避免這種情況。
內插邊界處理#
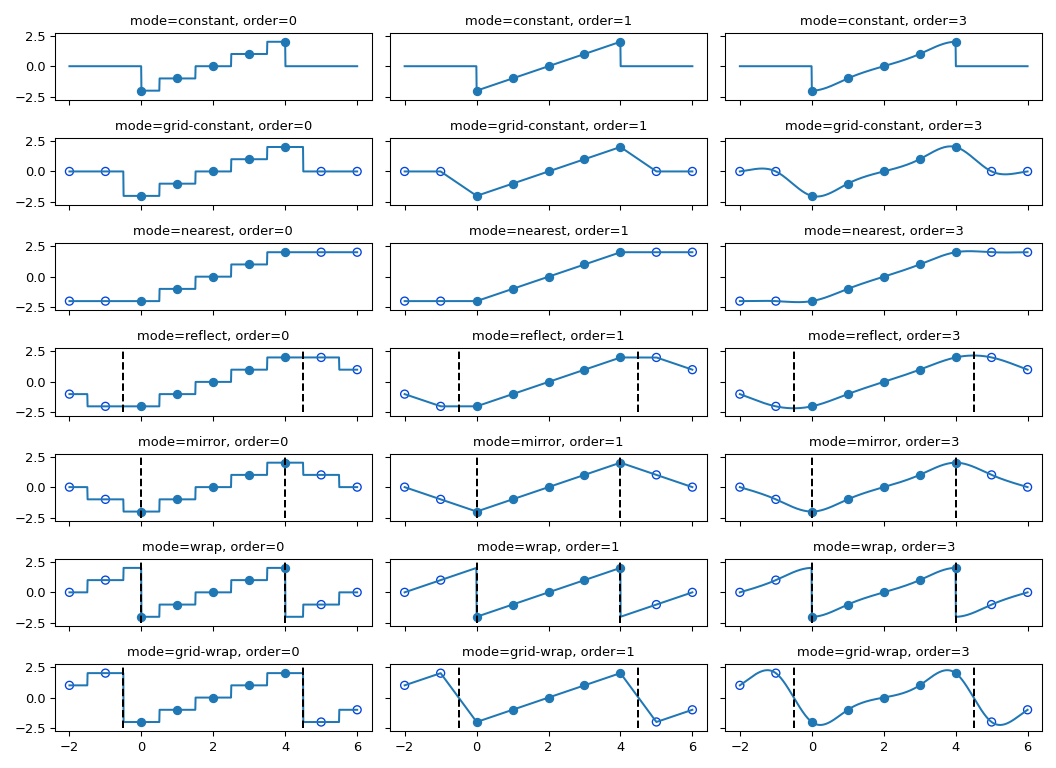
所有內插函數都採用樣條內插來影響輸入陣列的某種類型的幾何變換。這需要將輸出座標映射到輸入座標,因此,可能會出現需要邊界外輸入值的情況。此問題的解決方式與 濾波器函數 中針對多維濾波器函數描述的方式相同。因此,這些函數都支援 mode 參數,該參數決定如何處理邊界,以及 cval 參數,該參數在使用 ‘constant’ 模式的情況下提供常數值。所有模式的行為,包括在非整數位置的行為,如下所示。請注意,並非所有模式的邊界處理方式都相同;reflect (又名 grid-mirror) 和 grid-wrap 涉及關於影像樣本之間一半位置的點(虛線垂直線)的對稱性或重複性,而模式 mirror 和 wrap 將影像視為其範圍正好在第一個和最後一個樣本點結束,而不是超過 0.5 個樣本。
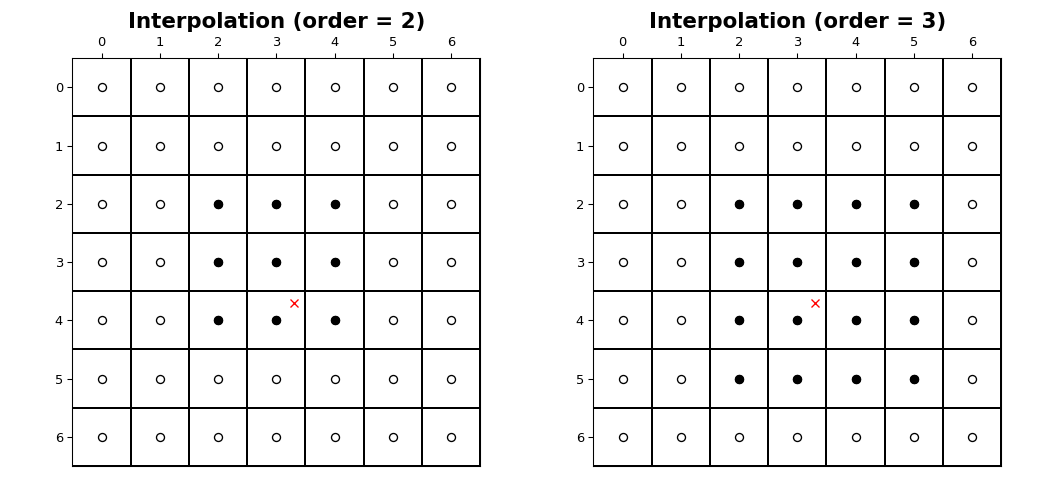
影像樣本的座標落在每個軸 i 上從 0 到 shape[i] - 1 的整數取樣位置。下圖說明了在形狀為 (7, 7) 的影像中,在位置 (3.7, 3.3) 處的點的內插。對於 n 階的內插,每個軸上都涉及 n + 1 個樣本。填滿的圓圈說明了參與紅色 x 位置處的值內插的取樣位置。
內插函數#
geometric_transform函數將任意幾何變換應用於輸入。在輸出中的每個點呼叫給定的 mapping 函數,以找到輸入中對應的座標。mapping 必須是可呼叫的物件,它接受長度等於輸出陣列秩的元組,並傳回對應的輸入座標作為長度等於輸入陣列秩的元組。可以選擇性地提供輸出形狀和輸出類型。如果未給定,它們將等於輸入形狀和類型。例如
>>> a = np.arange(12).reshape(4,3).astype(np.float64) >>> def shift_func(output_coordinates): ... return (output_coordinates[0] - 0.5, output_coordinates[1] - 0.5) ... >>> from scipy.ndimage import geometric_transform >>> geometric_transform(a, shift_func) array([[ 0. , 0. , 0. ], [ 0. , 1.3625, 2.7375], [ 0. , 4.8125, 6.1875], [ 0. , 8.2625, 9.6375]])
可以選擇性地定義額外引數並傳遞給濾波器函數。extra_arguments 和 extra_keywords 引數可用於傳遞額外引數的元組和/或具名引數的字典,這些引數在每次呼叫時都會傳遞給導數。例如,我們可以在範例中將位移作為引數傳遞
>>> def shift_func(output_coordinates, s0, s1): ... return (output_coordinates[0] - s0, output_coordinates[1] - s1) ... >>> geometric_transform(a, shift_func, extra_arguments = (0.5, 0.5)) array([[ 0. , 0. , 0. ], [ 0. , 1.3625, 2.7375], [ 0. , 4.8125, 6.1875], [ 0. , 8.2625, 9.6375]])
或
>>> geometric_transform(a, shift_func, extra_keywords = {'s0': 0.5, 's1': 0.5}) array([[ 0. , 0. , 0. ], [ 0. , 1.3625, 2.7375], [ 0. , 4.8125, 6.1875], [ 0. , 8.2625, 9.6375]])
注意
映射函數也可以用 C 語言編寫,並使用
scipy.LowLevelCallable傳遞。有關更多資訊,請參閱 在 C 中擴充 scipy.ndimage。map_coordinates函數使用給定的座標陣列應用任意座標變換。輸出的形狀是透過捨棄座標陣列的第一個軸來導出的。參數 coordinates 用於為輸出中的每個點找到輸入中對應的座標。coordinates 沿第一個軸的值是輸入陣列中找到輸出值的座標。(另請參閱 numarray coordinates 函數。)由於座標可能是非整數座標,因此輸入在這些座標處的值由請求階數的樣條內插確定。這是一個在
(0.5, 0.5)和(1, 2)處內插 2D 陣列的範例>>> a = np.arange(12).reshape(4,3).astype(np.float64) >>> a array([[ 0., 1., 2.], [ 3., 4., 5.], [ 6., 7., 8.], [ 9., 10., 11.]]) >>> from scipy.ndimage import map_coordinates >>> map_coordinates(a, [[0.5, 2], [0.5, 1]]) array([ 1.3625, 7.])
affine_transform函數將仿射變換應用於輸入陣列。給定的變換 matrix 和 offset 用於為輸出中的每個點找到輸入中對應的座標。輸入在計算出的座標處的值由請求階數的樣條內插確定。變換 matrix 必須是 2-D,或者也可以作為 1-D 序列或陣列給定。在後一種情況下,假定矩陣是對角矩陣。然後應用更有效率的內插演算法,該演算法利用問題的可分離性。可以選擇性地提供輸出形狀和輸出類型。如果未給定,它們將等於輸入形狀和類型。shift函數傳回輸入的位移版本,使用請求的 order 的樣條內插。zoom函數傳回輸入的重新縮放版本,使用請求的 order 的樣條內插。rotate函數傳回在由參數 axes 給定的兩個軸定義的平面中旋轉的輸入陣列,使用請求的 order 的樣條內插。角度必須以度為單位給定。如果 reshape 為 true,則調整輸出陣列的大小以包含旋轉的輸入。
形態學#
二元形態學#
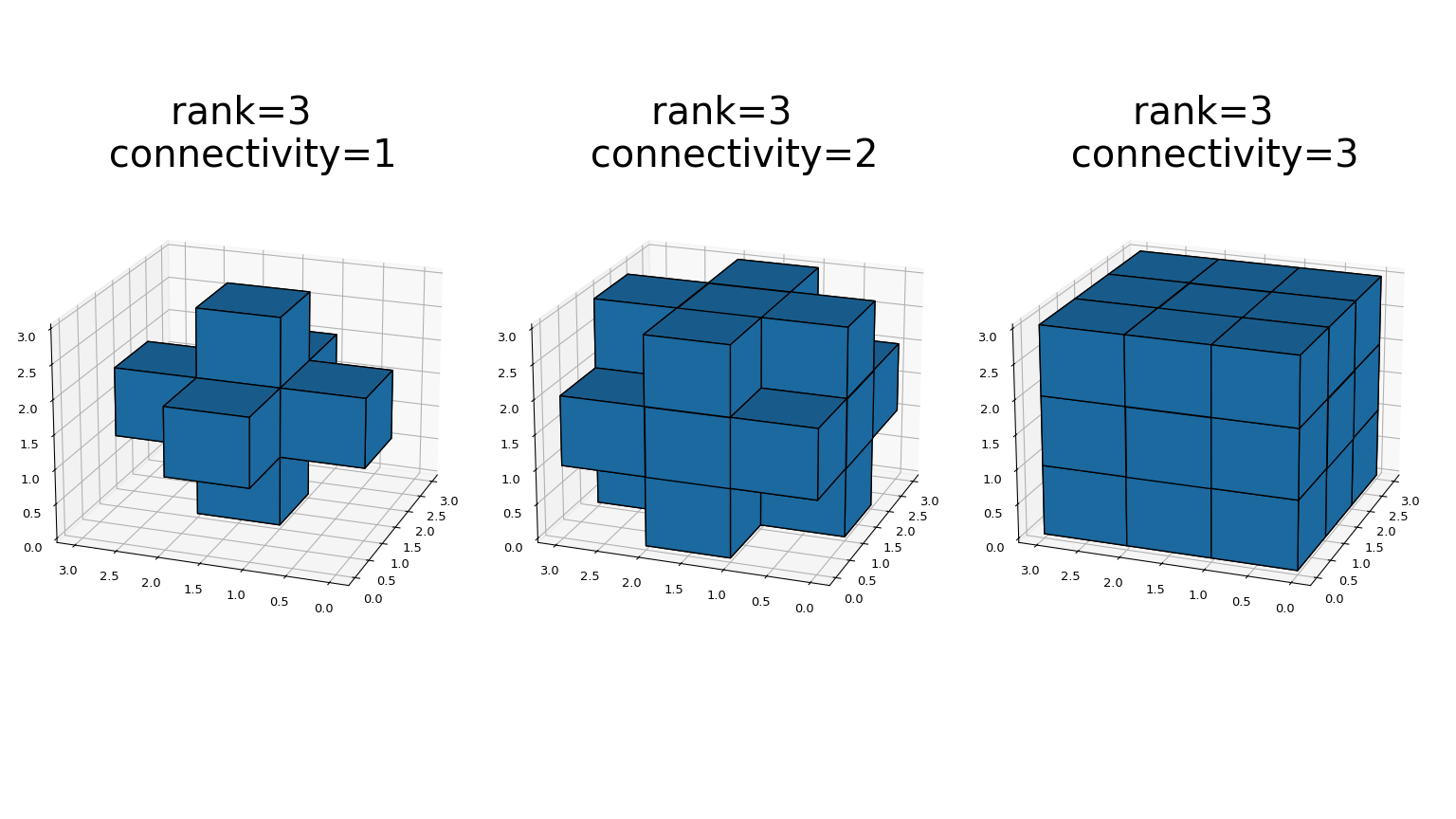
generate_binary_structure函數產生用於二元形態學操作的二元結構元素。必須提供結構的 rank。傳回的結構大小在每個方向上都等於三。如果從元素到中心的歐幾里得距離平方小於或等於 connectivity,則每個元素的值等於一。例如,2-D 4 連通和 8 連通結構產生如下>>> from scipy.ndimage import generate_binary_structure >>> generate_binary_structure(2, 1) array([[False, True, False], [ True, True, True], [False, True, False]], dtype=bool) >>> generate_binary_structure(2, 2) array([[ True, True, True], [ True, True, True], [ True, True, True]], dtype=bool)
這是 generate_binary_structure 在 3D 中的視覺呈現
大多數二元形態學函數可以用基本操作腐蝕和膨脹來表示,可以在這裡看到
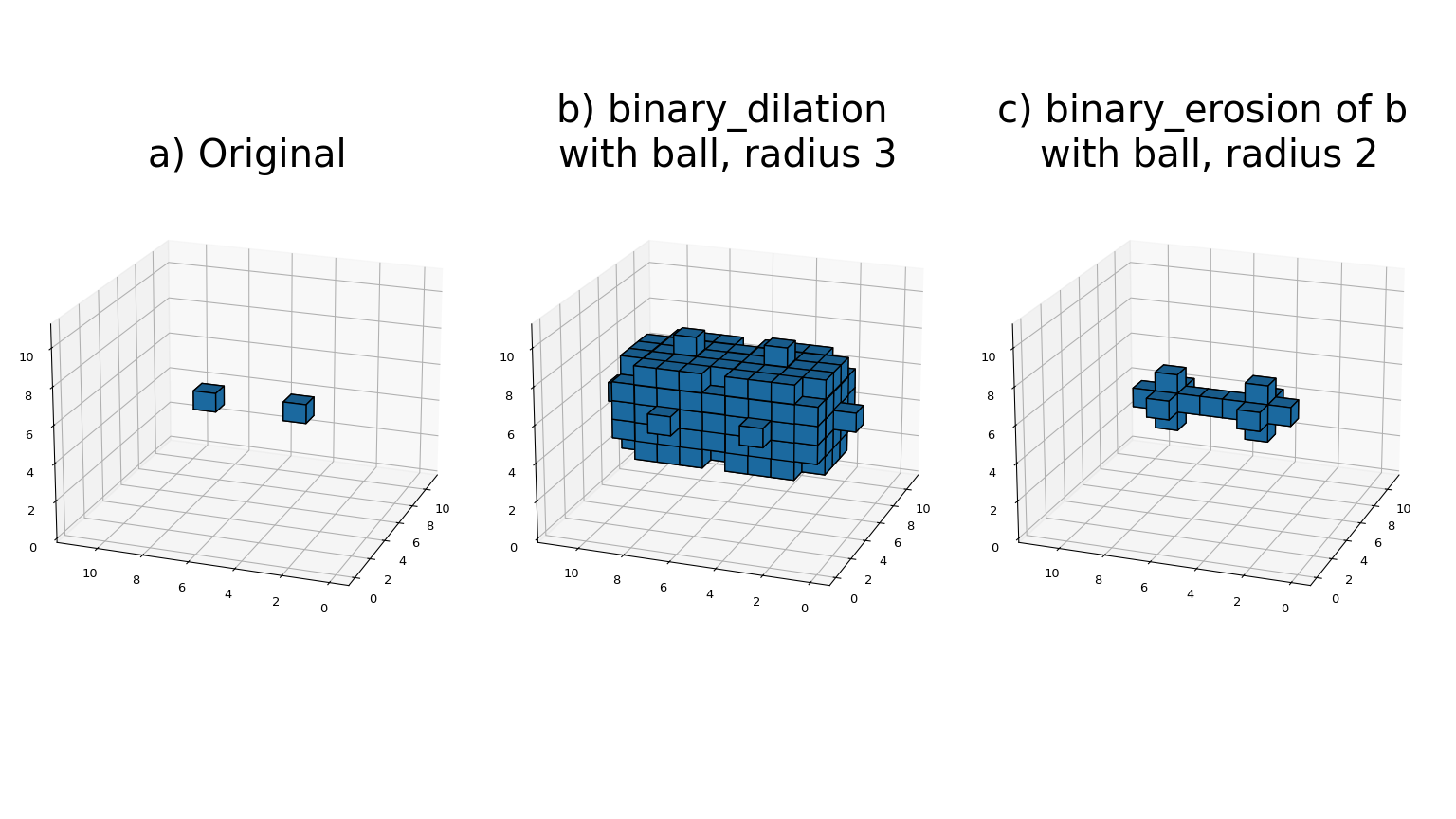
binary_erosion函數使用給定的結構元素實作任意秩陣列的二元腐蝕。origin 參數控制結構元素的放置,如 濾波器函數 中所述。如果未提供結構元素,則使用generate_binary_structure產生連通性等於一的元素。border_value 參數給出邊界外陣列的值。腐蝕重複 iterations 次。如果 iterations 小於 1,則腐蝕會重複執行,直到結果不再改變為止。如果給定 mask 陣列,則在每次迭代中僅修改在對應遮罩元素處具有 true 值的元素。binary_dilation函數使用給定的結構元素實作任意秩陣列的二元膨脹。origin 參數控制結構元素的放置,如 濾波器函數 中所述。如果未提供結構元素,則使用generate_binary_structure產生連通性等於一的元素。border_value 參數給出邊界外陣列的值。膨脹重複 iterations 次。如果 iterations 小於 1,則膨脹會重複執行,直到結果不再改變為止。如果給定 mask 陣列,則在每次迭代中僅修改在對應遮罩元素處具有 true 值的元素。
以下是使用 binary_dilation 透過使用資料陣列作為遮罩,從邊界重複膨脹空陣列來找到所有接觸邊界的元素的範例
>>> struct = np.array([[0, 1, 0], [1, 1, 1], [0, 1, 0]])
>>> a = np.array([[1,0,0,0,0], [1,1,0,1,0], [0,0,1,1,0], [0,0,0,0,0]])
>>> a
array([[1, 0, 0, 0, 0],
[1, 1, 0, 1, 0],
[0, 0, 1, 1, 0],
[0, 0, 0, 0, 0]])
>>> from scipy.ndimage import binary_dilation
>>> binary_dilation(np.zeros(a.shape), struct, -1, a, border_value=1)
array([[ True, False, False, False, False],
[ True, True, False, False, False],
[False, False, False, False, False],
[False, False, False, False, False]], dtype=bool)
binary_erosion 和 binary_dilation 函數都具有 iterations 參數,該參數允許腐蝕或膨脹重複執行多次。使用給定結構重複腐蝕或膨脹 n 次等同於使用自身膨脹 n-1 次的結構進行腐蝕或膨脹。提供了一個函數,允許計算自身膨脹多次的結構
iterate_structure函數透過將輸入結構與自身膨脹 iteration - 1 次來傳回結構。例如
>>> struct = generate_binary_structure(2, 1) >>> struct array([[False, True, False], [ True, True, True], [False, True, False]], dtype=bool) >>> from scipy.ndimage import iterate_structure >>> iterate_structure(struct, 2) array([[False, False, True, False, False], [False, True, True, True, False], [ True, True, True, True, True], [False, True, True, True, False], [False, False, True, False, False]], dtype=bool) If the origin of the original structure is equal to 0, then it is also equal to 0 for the iterated structure. If not, the origin must also be adapted if the equivalent of the *iterations* erosions or dilations must be achieved with the iterated structure. The adapted origin is simply obtained by multiplying with the number of iterations. For convenience, the :func:`iterate_structure` also returns the adapted origin if the *origin* parameter is not ``None``: .. code:: python >>> iterate_structure(struct, 2, -1) (array([[False, False, True, False, False], [False, True, True, True, False], [ True, True, True, True, True], [False, True, True, True, False], [False, False, True, False, False]], dtype=bool), [-2, -2])
其他形態學操作可以用腐蝕和膨脹來定義。以下函數為了方便起見提供了一些這些操作
binary_opening函數使用給定的結構元素實作任意秩陣列的二元開運算。二元開運算等同於二元腐蝕,後跟使用相同結構元素的二元膨脹。origin 參數控制結構元素的放置,如 濾波器函數 中所述。如果未提供結構元素,則使用generate_binary_structure產生連通性等於一的元素。iterations 參數給出執行的腐蝕次數,後跟相同次數的膨脹。binary_closing函數使用給定的結構元素實作任意秩陣列的二元閉運算。二元閉運算等同於二元膨脹,後跟使用相同結構元素的二元腐蝕。origin 參數控制結構元素的放置,如 濾波器函數 中所述。如果未提供結構元素,則使用generate_binary_structure產生連通性等於一的元素。iterations 參數給出執行的膨脹次數,後跟相同次數的腐蝕。binary_fill_holes函數用於閉合二元影像中物件的孔洞,其中結構定義了孔洞的連通性。origin 參數控制結構元素的放置,如 濾波器函數 中所述。如果未提供結構元素,則使用generate_binary_structure產生連通性等於一的元素。binary_hit_or_miss函數使用給定的結構元素實作任意秩陣列的二元擊中或錯失變換。擊中或錯失變換是透過使用第一個結構腐蝕輸入、使用第二個結構腐蝕輸入的邏輯 not,然後對這兩個腐蝕執行邏輯 and 來計算的。origin 參數控制結構元素的放置,如 濾波器函數 中所述。如果 origin2 等於None,則將其設定為等於 origin1 參數。如果未提供第一個結構元素,則使用generate_binary_structure產生連通性等於一的結構元素。如果未提供 structure2,則將其設定為等於 structure1 的邏輯 not。
灰階形態學#
灰階形態學操作是二元形態學操作的等效操作,適用於具有任意值的陣列。下面,我們描述了腐蝕、膨脹、開運算和閉運算的灰階等效操作。這些操作的實作方式與 濾波器函數 中描述的濾波器類似,我們參考本節以了解濾波器核心和足跡的描述,以及陣列邊界的處理。灰階形態學操作可以選擇性地採用 structure 參數,該參數給出結構元素的值。如果未給定此參數,則假定結構元素是平坦的,值等於零。結構的形狀可以選擇性地由 footprint 參數定義。如果未給定此參數,則假定結構是矩形的,大小等於 structure 陣列的維度,或者如果未給定 structure,則由 size 參數定義。size 參數僅在未給定 structure 和 footprint 的情況下使用,在這種情況下,假定結構元素是矩形且平坦的,維度由 size 給定。如果提供 size 參數,則必須是大小序列或單個數字,在這種情況下,假定濾波器的大小沿每個軸都相等。如果提供 footprint 參數,則必須是一個陣列,該陣列透過其非零元素定義核心的形狀。
與二元腐蝕和膨脹類似,灰階腐蝕和膨脹也有操作
grey_erosion函數計算多維灰階腐蝕。grey_dilation函數計算多維灰階膨脹。
灰階開運算和閉運算可以類似於其二元對應物來定義
grey_opening函數實作任意秩陣列的灰階開運算。灰階開運算等同於灰階腐蝕,後跟灰階膨脹。grey_closing函數實作任意秩陣列的灰階閉運算。灰階開運算等同於灰階膨脹,後跟灰階腐蝕。morphological_gradient函數實作任意秩陣列的灰階形態學梯度。灰階形態學梯度等於灰階膨脹和灰階腐蝕的差值。morphological_laplace函數實作任意秩陣列的灰階形態學拉普拉斯算子。灰階形態學拉普拉斯算子等於灰階膨脹和灰階腐蝕之和減去兩倍的輸入。white_tophat函數實作任意秩陣列的白色頂帽濾波器。白色頂帽等於輸入和灰階開運算的差值。black_tophat函數實作任意秩陣列的黑色頂帽濾波器。黑色頂帽等於灰階閉運算和輸入的差值。
距離變換#
距離變換用於計算物件的每個元素到背景的最小距離。以下函數實作了三種不同距離度量的距離變換:歐幾里得距離、城市街區距離和棋盤距離。
distance_transform_cdt函數使用倒角類型演算法來計算輸入的距離變換,方法是將每個物件元素(由大於零的值定義)替換為到背景(所有非物件元素)的最短距離。結構決定了執行的倒角類型。如果結構等於 ‘cityblock’,則使用generate_binary_structure產生結構,平方距離等於 1。如果結構等於 ‘chessboard’,則使用generate_binary_structure產生結構,平方距離等於陣列的秩。這些選擇對應於二維城市街區和棋盤距離度量的常見解釋。除了距離變換之外,還可以計算特徵變換。在這種情況下,最接近的背景元素的索引沿結果的第一個軸傳回。return_distances 和 return_indices 旗標可用於指示是否必須傳回距離變換、特徵變換或兩者。
distances 和 indices 引數可用於給出可選的輸出陣列,這些陣列必須具有正確的大小和類型(均為
numpy.int32)。用於實作此函數的演算法基礎知識在 [2] 中描述。distance_transform_edt函數計算輸入的精確歐幾里得距離變換,方法是將每個物件元素(由大於零的值定義)替換為到背景(所有非物件元素)的最短歐幾里得距離。除了距離變換之外,還可以計算特徵變換。在這種情況下,最接近的背景元素的索引沿結果的第一個軸傳回。return_distances 和 return_indices 旗標可用於指示是否必須傳回距離變換、特徵變換或兩者。
可以選擇性地透過 sampling 參數給出沿每個軸的取樣,sampling 參數應為長度等於輸入秩的序列,或一個單個數字,在這種情況下,假定沿所有軸的取樣都相等。
distances 和 indices 引數可用於給出可選的輸出陣列,這些陣列必須具有正確的大小和類型(
numpy.float64和numpy.int32)。用於實作此函數的演算法在 [3] 中描述。distance_transform_bf函數使用暴力演算法來計算輸入的距離變換,方法是將每個物件元素(由大於零的值定義)替換為到背景(所有非物件元素)的最短距離。度量必須是 “euclidean”、“cityblock” 或 “chessboard” 之一。除了距離變換之外,還可以計算特徵變換。在這種情況下,最接近的背景元素的索引沿結果的第一個軸傳回。return_distances 和 return_indices 旗標可用於指示是否必須傳回距離變換、特徵變換或兩者。
可以選擇性地透過 sampling 參數給出沿每個軸的取樣,sampling 參數應為長度等於輸入秩的序列,或一個單個數字,在這種情況下,假定沿所有軸的取樣都相等。此參數僅在歐幾里得距離變換的情況下使用。
distances 和 indices 引數可用於給出可選的輸出陣列,這些陣列必須具有正確的大小和類型(
numpy.float64和numpy.int32)。注意
此函數使用慢速的暴力演算法。
distance_transform_cdt函數可以用於更有效率地計算城市街區和棋盤距離轉換。distance_transform_edt函數可以用於更有效率地計算精確的歐幾里德距離轉換。
影像分割與標記#
影像分割是將感興趣的物件從背景中分離出來的過程。最簡單的方法可能是強度閾值處理,這可以很容易地使用 numpy 函數來完成
>>> a = np.array([[1,2,2,1,1,0],
... [0,2,3,1,2,0],
... [1,1,1,3,3,2],
... [1,1,1,1,2,1]])
>>> np.where(a > 1, 1, 0)
array([[0, 1, 1, 0, 0, 0],
[0, 1, 1, 0, 1, 0],
[0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 1, 0]])
結果會是二元影像,其中個別的物件仍然需要被識別和標記。label 函數會產生一個陣列,其中每個物件都被分配一個唯一的數字
label函數會產生一個陣列,其中輸入中的物件會以整數索引標記。它會傳回一個元組,其中包含物件標籤的陣列和找到的物件數量,除非給定了 output 參數,在這種情況下,只會傳回物件數量。物件的連通性由結構元素定義。例如,在 2D 中,使用 4 連通結構元素會得到>>> a = np.array([[0,1,1,0,0,0],[0,1,1,0,1,0],[0,0,0,1,1,1],[0,0,0,0,1,0]]) >>> s = [[0, 1, 0], [1,1,1], [0,1,0]] >>> from scipy.ndimage import label >>> label(a, s) (array([[0, 1, 1, 0, 0, 0], [0, 1, 1, 0, 2, 0], [0, 0, 0, 2, 2, 2], [0, 0, 0, 0, 2, 0]], dtype=int32), 2)
這兩個物件不相連,因為我們無法放置結構元素,使其與兩個物件都重疊。然而,8 連通結構元素只會產生單一物件
>>> a = np.array([[0,1,1,0,0,0],[0,1,1,0,1,0],[0,0,0,1,1,1],[0,0,0,0,1,0]]) >>> s = [[1,1,1], [1,1,1], [1,1,1]] >>> label(a, s)[0] array([[0, 1, 1, 0, 0, 0], [0, 1, 1, 0, 1, 0], [0, 0, 0, 1, 1, 1], [0, 0, 0, 0, 1, 0]], dtype=int32)
如果沒有提供結構元素,則會透過呼叫
generate_binary_structure(請參閱二元形態學)使用連通性 1(在 2D 中是第一個範例的 4 連通結構)來產生一個。輸入可以是任何類型,任何不等於零的值都被視為物件的一部分。如果您需要「重新標記」物件索引陣列(例如,在移除不需要的物件之後),這非常有用。只需再次將 label 函數應用於索引陣列即可。例如>>> l, n = label([1, 0, 1, 0, 1]) >>> l array([1, 0, 2, 0, 3], dtype=int32) >>> l = np.where(l != 2, l, 0) >>> l array([1, 0, 0, 0, 3], dtype=int32) >>> label(l)[0] array([1, 0, 0, 0, 2], dtype=int32)
注意
label使用的結構元素假定為對稱的。
還有許多其他影像分割方法,例如,從可以透過導數濾波器獲得的物件邊界估計。一種這樣的方法是分水嶺分割。watershed_ift 函數會從一個陣列產生一個陣列,其中每個物件都被分配一個唯一的標籤,該陣列會定位物件邊界,例如,由梯度幅度濾波器產生。它使用一個包含物件初始標記的陣列
watershed_ift函數應用了從標記開始的分水嶺演算法,使用影像森林轉換,如 [4] 中所述。此函數的輸入是要應用轉換的陣列,以及一個標記陣列,該陣列透過唯一標籤指定物件,其中任何非零值都是標記。例如
>>> input = np.array([[0, 0, 0, 0, 0, 0, 0], ... [0, 1, 1, 1, 1, 1, 0], ... [0, 1, 0, 0, 0, 1, 0], ... [0, 1, 0, 0, 0, 1, 0], ... [0, 1, 0, 0, 0, 1, 0], ... [0, 1, 1, 1, 1, 1, 0], ... [0, 0, 0, 0, 0, 0, 0]], np.uint8) >>> markers = np.array([[1, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 2, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0]], np.int8) >>> from scipy.ndimage import watershed_ift >>> watershed_ift(input, markers) array([[1, 1, 1, 1, 1, 1, 1], [1, 1, 2, 2, 2, 1, 1], [1, 2, 2, 2, 2, 2, 1], [1, 2, 2, 2, 2, 2, 1], [1, 2, 2, 2, 2, 2, 1], [1, 1, 2, 2, 2, 1, 1], [1, 1, 1, 1, 1, 1, 1]], dtype=int8)
在這裡,使用了兩個標記來指定一個物件(marker = 2)和背景(marker = 1)。它們被處理的順序是任意的:將背景的標記移動到陣列的右下角會產生不同的結果
>>> markers = np.array([[0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 2, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 1]], np.int8) >>> watershed_ift(input, markers) array([[1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1], [1, 1, 2, 2, 2, 1, 1], [1, 1, 2, 2, 2, 1, 1], [1, 1, 2, 2, 2, 1, 1], [1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1]], dtype=int8)
結果是物件(marker = 2)更小,因為第二個標記較早被處理。如果第一個標記應該指定背景物件,則這可能不是期望的效果。因此,
watershed_ift將具有負值的標記明確地視為背景標記,並在正常標記之後處理它們。例如,將第一個標記替換為負標記會產生與第一個範例類似的結果>>> markers = np.array([[0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 2, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, -1]], np.int8) >>> watershed_ift(input, markers) array([[-1, -1, -1, -1, -1, -1, -1], [-1, -1, 2, 2, 2, -1, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, -1, 2, 2, 2, -1, -1], [-1, -1, -1, -1, -1, -1, -1]], dtype=int8)
物件的連通性由結構元素定義。如果沒有提供結構元素,則會透過呼叫
generate_binary_structure(請參閱二元形態學)使用連通性 1(在 2D 中是 4 連通結構)來產生一個。例如,在上一個範例中使用 8 連通結構會產生不同的物件>>> watershed_ift(input, markers, ... structure = [[1,1,1], [1,1,1], [1,1,1]]) array([[-1, -1, -1, -1, -1, -1, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, -1, -1, -1, -1, -1, -1]], dtype=int8)
注意
watershed_ift的實作將輸入的資料類型限制為numpy.uint8和numpy.uint16。
物件量測#
給定一個標記物件的陣列,可以量測個別物件的屬性。find_objects 函數可以用於產生一個切片列表,對於每個物件,給出完全包含該物件的最小子陣列
find_objects函數會在標記陣列中找到所有物件,並傳回一個切片列表,該列表對應於陣列中包含物件的最小區域。例如
>>> a = np.array([[0,1,1,0,0,0],[0,1,1,0,1,0],[0,0,0,1,1,1],[0,0,0,0,1,0]]) >>> l, n = label(a) >>> from scipy.ndimage import find_objects >>> f = find_objects(l) >>> a[f[0]] array([[1, 1], [1, 1]]) >>> a[f[1]] array([[0, 1, 0], [1, 1, 1], [0, 1, 0]])
find_objects函數會傳回所有物件的切片,除非 max_label 參數大於零,在這種情況下,只會傳回前 max_label 個物件。如果 label 陣列中缺少索引,則會傳回None而不是切片。例如>>> from scipy.ndimage import find_objects >>> find_objects([1, 0, 3, 4], max_label = 3) [(slice(0, 1, None),), None, (slice(2, 3, None),)]
find_objects 產生的切片列表對於查找陣列中物件的位置和尺寸很有用,但也可以用於對個別物件執行量測。假設,我們想要找到影像中物件的強度總和
>>> image = np.arange(4 * 6).reshape(4, 6)
>>> mask = np.array([[0,1,1,0,0,0],[0,1,1,0,1,0],[0,0,0,1,1,1],[0,0,0,0,1,0]])
>>> labels = label(mask)[0]
>>> slices = find_objects(labels)
然後我們可以計算第二個物件中元素的總和
>>> np.where(labels[slices[1]] == 2, image[slices[1]], 0).sum()
80
然而,這不是特別有效率,對於其他類型的量測也可能更複雜。因此,定義了一些量測函數,它們接受物件標籤的陣列和要量測的物件的索引。例如,計算強度總和可以透過以下方式完成
>>> from scipy.ndimage import sum as ndi_sum
>>> ndi_sum(image, labels, 2)
80
對於大型陣列和小物件,在切片陣列後呼叫量測函數更有效率
>>> ndi_sum(image[slices[1]], labels[slices[1]], 2)
80
或者,我們可以透過單一函數呼叫來量測多個標籤,並傳回結果列表。例如,為了量測範例中背景和第二個物件的值總和,我們給定一個標籤列表
>>> ndi_sum(image, labels, [0, 2])
array([178.0, 80.0])
以下描述的量測函數都支援 index 參數,以指示應量測哪個或哪些物件。index 的預設值為 None。這表示所有標籤大於零的元素都應被視為單一物件並進行量測。因此,在這種情況下,labels 陣列被視為由大於零的元素定義的遮罩。如果 index 是一個數字或數字序列,則它會給出要量測的物件的標籤。如果 index 是一個序列,則會傳回結果列表。如果 index 是單一數字,則傳回多個結果的函數會將其結果作為元組傳回,如果 index 是序列,則傳回元組列表。
sum函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的元素總和。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。mean函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的元素平均值。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。variance函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的元素變異數。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。standard_deviation函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的元素標準差。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。minimum函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的元素最小值。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。maximum函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的元素最大值。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。minimum_position函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的元素最小值位置。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。maximum_position函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的元素最大值位置。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。extrema函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的元素的最小值、最大值及其位置。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。結果是一個元組,給出最小值、最大值、最小值的位置和最大值的位置。結果與由上述函數 minimum、maximum、minimum_position 和 maximum_position 的結果形成的元組相同。center_of_mass函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的質心。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。histogram函數使用 labels 陣列作為物件標籤,計算標籤由 index 給定的物件的直方圖。如果 index 是None,則所有具有非零標籤值的元素都被視為單一物件。如果 label 是None,則 input 的所有元素都會用於計算。直方圖由其最小值 (min)、最大值 (max) 和 bin 的數量 (bins) 定義。它們以numpy.int32類型的 1-D 陣列形式傳回。
在 C 語言中擴展 scipy.ndimage#
scipy.ndimage 中的一些函數接受回呼引數。這可以是 Python 函數,也可以是包含 C 函數指標的 scipy.LowLevelCallable。使用 C 函數通常會更有效率,因為它可以避免在陣列的許多元素上呼叫 Python 函數的額外開銷。若要使用 C 函數,您必須編寫一個 C 擴充模組,其中包含回呼函數和一個 Python 函數,該函數傳回一個 scipy.LowLevelCallable,其中包含指向回呼的指標。
支援回呼的函數範例是 geometric_transform,它接受一個回呼函數,該函數定義了從所有輸出座標到輸入陣列中對應座標的映射。請考慮以下 Python 範例,它使用 geometric_transform 來實作 shift 函數。
from scipy import ndimage
def transform(output_coordinates, shift):
input_coordinates = output_coordinates[0] - shift, output_coordinates[1] - shift
return input_coordinates
im = np.arange(12).reshape(4, 3).astype(np.float64)
shift = 0.5
print(ndimage.geometric_transform(im, transform, extra_arguments=(shift,)))
我們也可以使用以下 C 程式碼實作回呼函數
/* example.c */
#include <Python.h>
#include <numpy/npy_common.h>
static int
_transform(npy_intp *output_coordinates, double *input_coordinates,
int output_rank, int input_rank, void *user_data)
{
npy_intp i;
double shift = *(double *)user_data;
for (i = 0; i < input_rank; i++) {
input_coordinates[i] = output_coordinates[i] - shift;
}
return 1;
}
static char *transform_signature = "int (npy_intp *, double *, int, int, void *)";
static PyObject *
py_get_transform(PyObject *obj, PyObject *args)
{
if (!PyArg_ParseTuple(args, "")) return NULL;
return PyCapsule_New(_transform, transform_signature, NULL);
}
static PyMethodDef ExampleMethods[] = {
{"get_transform", (PyCFunction)py_get_transform, METH_VARARGS, ""},
{NULL, NULL, 0, NULL}
};
/* Initialize the module */
static struct PyModuleDef example = {
PyModuleDef_HEAD_INIT,
"example",
NULL,
-1,
ExampleMethods,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_example(void)
{
return PyModule_Create(&example);
}
有關編寫 Python 擴充模組的更多資訊,請參閱這裡。如果 C 程式碼在檔案 example.c 中,則在將其新增至 meson.build 後即可編譯(請參閱 meson.build 檔案中的範例)並遵循其中的內容。完成後,執行腳本
import ctypes
import numpy as np
from scipy import ndimage, LowLevelCallable
from example import get_transform
shift = 0.5
user_data = ctypes.c_double(shift)
ptr = ctypes.cast(ctypes.pointer(user_data), ctypes.c_void_p)
callback = LowLevelCallable(get_transform(), ptr)
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
產生與原始 Python 腳本相同的結果。
在 C 版本中,_transform 是回呼函數,參數 output_coordinates 和 input_coordinates 的作用與 Python 版本相同,而 output_rank 和 input_rank 提供了 len(output_coordinates) 和 len(input_coordinates) 的等效項。變數 shift 透過 user_data 而不是 extra_arguments 傳遞。最後,C 回呼函數傳回整數狀態,成功時為 1,否則為零。
函數 py_transform 將回呼函數包裝在 PyCapsule 中。主要步驟是
初始化
PyCapsule。第一個引數是指向回呼函數的指標。第二個引數是函數簽名,它必須與
ndimage預期的簽名完全匹配。上面,我們使用
scipy.LowLevelCallable來指定我們使用ctypes產生的user_data。另一種方法是在 capsule 上下文中提供資料,這可以透過 PyCapsule_SetContext 設定,並省略在
scipy.LowLevelCallable中指定user_data。但是,在這種方法中,我們需要處理資料的分配/釋放 — 在 capsule 被銷毀後釋放資料可以透過在 PyCapsule_New 的第三個引數中指定非 NULL 回呼函數來完成。
ndimage 的 C 回呼函數都遵循此方案。下一節列出了接受 C 回呼函數的 ndimage 函數,並給出了函數的原型。
下面,我們展示了使用 Numba、Cython、ctypes 或 cffi 而不是在 C 語言中編寫包裝程式碼的替代方法。
Numba
Numba 提供了一種在 Python 中輕鬆編寫低階函數的方法。我們可以像下面這樣使用 Numba 編寫上述程式碼
# example.py
import numpy as np
import ctypes
from scipy import ndimage, LowLevelCallable
from numba import cfunc, types, carray
@cfunc(types.intc(types.CPointer(types.intp),
types.CPointer(types.double),
types.intc,
types.intc,
types.voidptr))
def transform(output_coordinates_ptr, input_coordinates_ptr,
output_rank, input_rank, user_data):
input_coordinates = carray(input_coordinates_ptr, (input_rank,))
output_coordinates = carray(output_coordinates_ptr, (output_rank,))
shift = carray(user_data, (1,), types.double)[0]
for i in range(input_rank):
input_coordinates[i] = output_coordinates[i] - shift
return 1
shift = 0.5
# Then call the function
user_data = ctypes.c_double(shift)
ptr = ctypes.cast(ctypes.pointer(user_data), ctypes.c_void_p)
callback = LowLevelCallable(transform.ctypes, ptr)
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
Cython
與上述程式碼功能相同的程式碼可以使用 Cython 以較少的樣板程式碼編寫如下
# example.pyx
from numpy cimport npy_intp as intp
cdef api int transform(intp *output_coordinates, double *input_coordinates,
int output_rank, int input_rank, void *user_data):
cdef intp i
cdef double shift = (<double *>user_data)[0]
for i in range(input_rank):
input_coordinates[i] = output_coordinates[i] - shift
return 1
# script.py
import ctypes
import numpy as np
from scipy import ndimage, LowLevelCallable
import example
shift = 0.5
user_data = ctypes.c_double(shift)
ptr = ctypes.cast(ctypes.pointer(user_data), ctypes.c_void_p)
callback = LowLevelCallable.from_cython(example, "transform", ptr)
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
cffi
使用 cffi,您可以與駐留在共享程式庫 (DLL) 中的 C 函數介接。首先,我們需要編寫共享程式庫,我們在 C 語言中執行此操作 — 此範例適用於 Linux/OSX
/*
example.c
Needs to be compiled with "gcc -std=c99 -shared -fPIC -o example.so example.c"
or similar
*/
#include <stdint.h>
int
_transform(intptr_t *output_coordinates, double *input_coordinates,
int output_rank, int input_rank, void *user_data)
{
int i;
double shift = *(double *)user_data;
for (i = 0; i < input_rank; i++) {
input_coordinates[i] = output_coordinates[i] - shift;
}
return 1;
}
呼叫程式庫的 Python 程式碼是
import os
import numpy as np
from scipy import ndimage, LowLevelCallable
import cffi
# Construct the FFI object, and copypaste the function declaration
ffi = cffi.FFI()
ffi.cdef("""
int _transform(intptr_t *output_coordinates, double *input_coordinates,
int output_rank, int input_rank, void *user_data);
""")
# Open library
lib = ffi.dlopen(os.path.abspath("example.so"))
# Do the function call
user_data = ffi.new('double *', 0.5)
callback = LowLevelCallable(lib._transform, user_data)
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
您可以在 cffi 文件中找到更多資訊。
ctypes
使用 ctypes,C 程式碼和 so/DLL 的編譯與上述 cffi 相同。Python 程式碼不同
# script.py
import os
import ctypes
import numpy as np
from scipy import ndimage, LowLevelCallable
lib = ctypes.CDLL(os.path.abspath('example.so'))
shift = 0.5
user_data = ctypes.c_double(shift)
ptr = ctypes.cast(ctypes.pointer(user_data), ctypes.c_void_p)
# Ctypes has no built-in intptr type, so override the signature
# instead of trying to get it via ctypes
callback = LowLevelCallable(lib._transform, ptr,
"int _transform(intptr_t *, double *, int, int, void *)")
# Perform the call
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
您可以在 ctypes 文件中找到更多資訊。