基於多項式內插法的 CDF 反演 (PINV)#
必要項目:PDF
可選項目:CDF、眾數、中心
速度
設定:(非常) 慢
抽樣:(非常) 快
基於多項式內插法的 CDF 反演 (PINV) 是一種反演方法,僅需要密度函數即可從分佈中抽樣。它基於 PPF 的多項式內插法和 PDF 的高斯-洛巴托積分。它可以控制內插誤差和積分誤差。其主要目的是提供非常快速的抽樣,對於任何給定的分佈幾乎相同,但代價是中等到慢的設定時間。它是已知最快的固定參數情況反演方法。
反演方法是最簡單且最靈活的抽樣非均勻隨機變數的方法。對於具有 CDF \(F\) 的目標分佈和從 \(\text{Uniform}(0, 1)\) 抽樣的均勻隨機變數 \(U\),隨機變數 X 是通過使用分佈的 PPF(反向 CDF)轉換均勻隨機變數 \(U\) 生成的
由於其優點,此方法適用於隨機模擬。其中一些最吸引人的優點是
它保留了均勻隨機數抽樣器的結構特性。
將均勻隨機變數 \(U\) 一對一轉換為非均勻隨機變數 \(X\)。
易於且有效率地從截斷分佈中抽樣。
遺憾的是,PPF 很少以封閉形式提供,或者在可用時速度太慢。對於許多分佈,CDF 也不容易獲得。此方法解決了這兩個缺點。使用者只需提供 PDF,以及可選的眾數附近點(稱為「中心」)以及最大可接受誤差的大小。它結合了自適應和簡單的高斯-洛巴托求積法來獲得 CDF,並使用牛頓內插法來獲得 PPF。此方法不是精確的,因為它僅產生近似分佈的隨機變數。儘管如此,最大容許近似誤差可以設定為接近機器精度。u 誤差的概念用於測量和控制誤差。它定義為
其中 \(u \in (0, 1)\) 是我們想要測量誤差的分位數,而 \(F^{-1}_a\) 是給定分佈的近似 PPF。
最大 u 誤差是數值計算 CDF 和 PPF 時的近似誤差準則。演算法的最大容許 u 誤差稱為演算法的 u 解析度,並以 \(\epsilon_{u}\) 表示
u 誤差的主要優點是,如果 CDF 可用,則可以輕鬆計算它。我們參考 [1] 以獲得更詳細的討論。
此外,此方法僅適用於有界分佈。在無限尾部的情況下,尾部的末端被截斷,使得其下的面積小於或等於 \(0.05\epsilon_{u}\)。
對於給定的分佈,存在一些限制
分佈的支援(即 PDF 嚴格為正的區域)必須是連通的。實際上,這表示 PDF「不太小」的區域必須是連通的。單峰密度滿足此條件。如果違反此條件,則可能會截斷分佈的域。
當 PDF 以數值方式積分時,給定的 PDF 必須是連續的並且應該是平滑的。
PDF 必須是有界的。
當分佈具有重尾(因為反向 CDF 在 0 或 1 處變得非常陡峭)並且請求的 u 解析度非常小時,演算法會出現問題。例如,當請求的 u 解析度小於 1.e-12 時,柯西分佈很可能顯示此問題。
以下四個步驟由演算法在設定期間執行
計算分佈的端點:如果給定有限支援,則跳過此步驟。否則,尾部的末端被截斷,使得其下的面積小於或等於 \(0.05\epsilon_{u}\)。
域被劃分為子區間以計算 CDF 和 PPF。
CDF 使用高斯-洛巴托求積法計算,使得積分誤差最多為 \(0.05I_{0}\epsilon_{u}\),其中 \(I_{0}\) 近似為 PDF 下的總面積。
PPF 使用牛頓內插公式計算,最大內插誤差為 \(0.9\epsilon_{u}\)。
要初始化產生器以從標準常態分佈中抽樣,請執行
>>> import numpy as np
>>> from scipy.stats.sampling import NumericalInversePolynomial
>>> class StandardNormal:
... def pdf(self, x):
... return np.exp(-0.5 * x*x)
...
>>> dist = StandardNormal()
>>> urng = np.random.default_rng()
>>> rng = NumericalInversePolynomial(dist, random_state=urng)
產生器已設定完成,我們可以開始從我們的分佈中抽樣
>>> rng.rvs((5, 3))
array([[-1.52449963, 1.31933688, 2.05884468],
[ 0.48883931, 0.15207903, -0.02150773],
[ 1.11486463, 1.95449597, -0.30724928],
[ 0.9854643 , 0.29867424, 0.7560304 ],
[-0.61776203, 0.16033378, -1.00933003]])
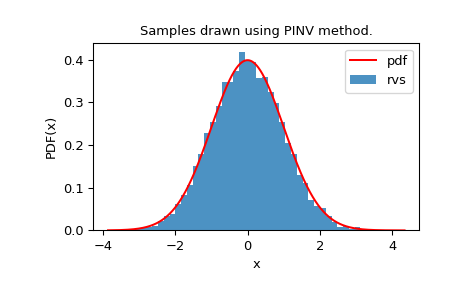
我們可以查看隨機變數的直方圖,以檢查它們與我們的分佈的擬合程度
>>> import matplotlib.pyplot as plt
>>> from scipy.stats import norm
>>> from scipy.stats.sampling import NumericalInversePolynomial
>>> class StandardNormal:
... def pdf(self, x):
... return np.exp(-0.5 * x*x)
...
>>> dist = StandardNormal()
>>> urng = np.random.default_rng()
>>> rng = NumericalInversePolynomial(dist, random_state=urng)
>>> rvs = rng.rvs(10000)
>>> x = np.linspace(rvs.min()-0.1, rvs.max()+0.1, num=10000)
>>> fx = norm.pdf(x)
>>> plt.plot(x, fx, "r-", label="pdf")
>>> plt.hist(rvs, bins=50, density=True, alpha=0.8, label="rvs")
>>> plt.xlabel("x")
>>> plt.ylabel("PDF(x)")
>>> plt.title("Samples drawn using PINV method.")
>>> plt.legend()
>>> plt.show()
最大容許誤差(即 u 解析度)可以通過在初始化期間傳遞 u_resolution 關鍵字來更改
>>> rng = NumericalInversePolynomial(dist, u_resolution=1e-12,
... random_state=urng)
這會導致 PPF 的更精確近似,並且產生的 RV 更緊密地遵循精確分佈。但是,請注意,它的代價是昂貴的設定。
設定時間主要取決於 PDF 的評估次數。對於難以評估的 PDF 來說,成本更高。請注意,我們可以忽略歸一化常數以加速 PDF 的評估。u_resolution 值越小,設定期間 PDF 評估的次數就越多。
>>> from scipy.stats.sampling import NumericalInversePolynomial
>>> class StandardNormal:
... def __init__(self):
... self.callbacks = 0
... def pdf(self, x):
... self.callbacks += 1
... return np.exp(-0.5 * x*x)
...
>>> dist = StandardNormal()
>>> urng = np.random.default_rng()
>>> # u_resolution = 10^-8
>>> # => less PDF evaluations required
>>> # => faster setup
>>> rng = NumericalInversePolynomial(dist, u_resolution=1e-8,
... random_state=urng)
>>> dist.callbacks
4095 # may vary
>>> dist.callbacks = 0 # reset the number of callbacks
>>> # u_resolution = 10^-10 (default)
>>> # => more PDF evaluations required
>>> # => slow setup
>>> rng = NumericalInversePolynomial(dist, u_resolution=1e-10,
... random_state=urng)
>>> dist.callbacks
11454 # may vary
>>> dist.callbacks = 0 # reset the number of callbacks
>>> # u_resolution = 10^-12
>>> # => lots of PDF evaluations required
>>> # => very slow setup
>>> rng = NumericalInversePolynomial(dist, u_resolution=1e-12,
... random_state=urng)
13902 # may vary
正如我們所看到的,所需的 PDF 評估次數非常高,快速的 PDF 對於演算法至關重要。但是,這有助於減少達到誤差目標所需的子區間數量,從而節省記憶體並使抽樣快速。NumericalInverseHermite 是一種類似的反演方法,它基於埃爾米特內插法反演 CDF,並通過 u 解析度提供對最大容許誤差的控制。但是,與 NumericalInversePolynomial 相比,它使用了更多的區間
>>> from scipy.stats.sampling import NumericalInverseHermite
>>> # NumericalInverseHermite accepts a `tol` parameter to set the
>>> # u-resolution of the generator.
>>> rng_hermite = NumericalInverseHermite(norm(), tol=1e-12)
>>> rng_hermite.intervals
3000
>>> rng_poly = NumericalInversePolynomial(norm(), u_resolution=1e-12)
>>> rng_poly.intervals
252
當分佈的精確 CDF 可用時,可以通過調用 u_error 方法來估計演算法實現的 u 誤差
>>> from scipy.special import ndtr
>>> class StandardNormal:
... def pdf(self, x):
... return np.exp(-0.5 * x*x)
... def cdf(self, x):
... return ndtr(x)
...
>>> dist = StandardNormal()
>>> urng = np.random.default_rng()
>>> rng = NumericalInversePolynomial(dist, random_state=urng)
>>> rng.u_error(sample_size=100_000)
UError(max_error=8.785949745515609e-11, mean_absolute_error=2.9307548109436816e-11)
u_error 運行蒙地卡羅模擬,使用給定的樣本數來估計 u 誤差。在上面的範例中,模擬使用 100,000 個樣本來近似 u 誤差。它在 UError 具名元組中傳回最大 u 誤差 (max_error) 和平均絕對 u 誤差 (mean_absolute_error)。正如我們所看到的,max_error 低於預設 u_resolution (1e-10)。
一旦產生器初始化,也可以評估給定分佈的 PPF
>>> rng.ppf(0.975)
1.959963985701268
>>> norm.ppf(0.975)
1.959963984540054
例如,我們可以利用此來檢查最大和平均絕對 u 誤差
>>> u = np.linspace(0.001, 0.999, num=1_000_000)
>>> u_errors = np.abs(u - dist.cdf(rng.ppf(u)))
>>> u_errors.max()
8.78600525666684e-11
>>> u_errors.mean()
2.9321444940323206e-11
產生器提供的近似 PPF 方法比分佈的精確 PPF 更快地評估。
在設定期間,儲存了 CDF 點表,可用於在建立產生器後近似 CDF
>>> rng.cdf(1.959963984540054)
0.9750000000042454
>>> norm.cdf(1.959963984540054)
0.975
我們可以利用此來檢查計算 CDF 時的積分誤差是否超過 \(0.05I_{0}\epsilon_{u}\)。此處 \(I_0\) 是 \(\sqrt{2\pi}\)(標準常態分佈的歸一化常數)
>>> x = np.linspace(-10, 10, num=100_000)
>>> x_error = np.abs(dist.cdf(x) - rng.cdf(x))
>>> x_error.max()
4.506062190046123e-12
>>> I0 = np.sqrt(2*np.pi)
>>> max_integration_error = 0.05 * I0 * 1e-10
>>> x_error.max() <= max_integration_error
True
設定期間計算的 CDF 表用於評估 CDF,並且僅需要一些進一步的微調。這減少了對 PDF 的呼叫,但由於微調步驟使用簡單的高斯-洛巴托求積法,因此 PDF 被多次呼叫,從而減慢了計算速度。