scipy.stats.vonmises_line#
- scipy.stats.vonmises_line = <scipy.stats._continuous_distns.vonmises_gen object>[source]#
馮·米塞斯 (Von Mises) 連續隨機變數。
作為
rv_continuous類別的實例,vonmises_line物件繼承了它的一系列通用方法(完整列表請見下方),並以針對此特定分佈的詳細資訊加以完善。另請參閱
scipy.stats.vonmises_fisher超球面上的馮·米塞斯-費雪 (Von-Mises Fisher) 分佈
註解
vonmises和vonmises_line的機率密度函數為\[f(x, \kappa) = \frac{ \exp(\kappa \cos(x)) }{ 2 \pi I_0(\kappa) }\]對於 \(-\pi \le x \le \pi\), \(\kappa \ge 0\)。\(I_0\) 是零階修正貝索函數 (
scipy.special.i0)。vonmises是一種循環分佈,它不將分佈限制在固定區間內。目前,SciPy 中沒有循環分佈框架。cdf的實作方式為cdf(x + 2*np.pi) == cdf(x) + 1。vonmises_line是相同的分佈,定義在實數線上的 \([-\pi, \pi]\) 區間。這是一個常規(即非循環)分佈。關於分佈參數的註解:
vonmises和vonmises_line將kappa作為形狀參數(集中度),並將loc作為位置(循環平均值)。接受scale參數,但它沒有任何作用。範例
導入必要的模組。
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from scipy.stats import vonmises
定義分佈參數。
>>> loc = 0.5 * np.pi # circular mean >>> kappa = 1 # concentration
透過
pdf方法計算x=0的機率密度。>>> vonmises.pdf(0, loc=loc, kappa=kappa) 0.12570826359722018
驗證百分位數函數
ppf反轉了累積分佈函數cdf,達到浮點數精確度。>>> x = 1 >>> cdf_value = vonmises.cdf(x, loc=loc, kappa=kappa) >>> ppf_value = vonmises.ppf(cdf_value, loc=loc, kappa=kappa) >>> x, cdf_value, ppf_value (1, 0.31489339900904967, 1.0000000000000004)
透過呼叫
rvs方法繪製 1000 個隨機變數。>>> sample_size = 1000 >>> sample = vonmises(loc=loc, kappa=kappa).rvs(sample_size)
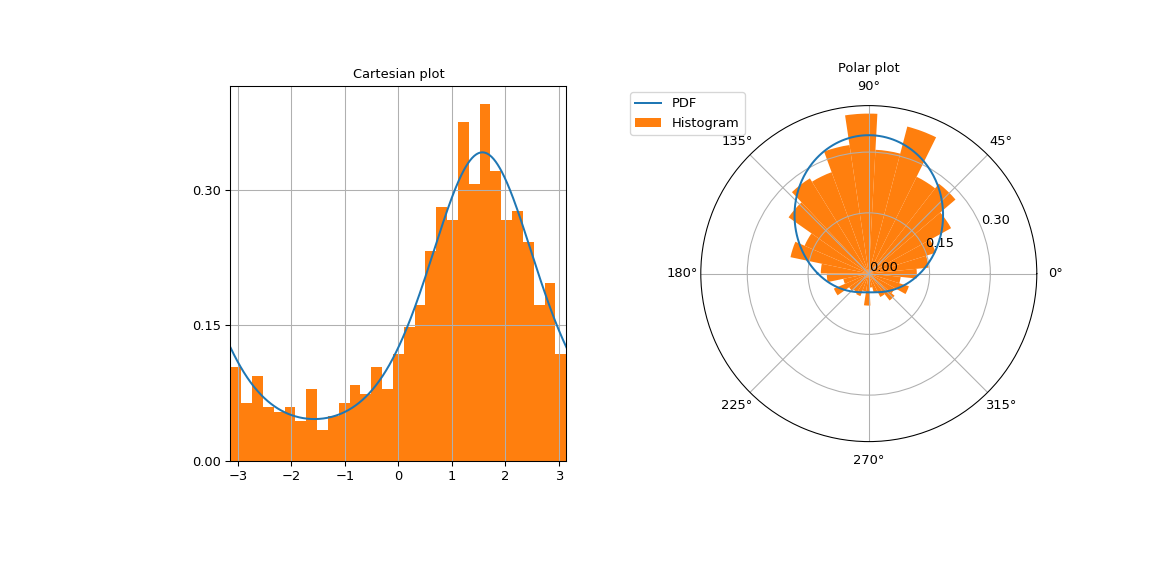
在笛卡爾和極座標網格上繪製馮·米塞斯密度圖,以強調它是一種循環分佈。
>>> fig = plt.figure(figsize=(12, 6)) >>> left = plt.subplot(121) >>> right = plt.subplot(122, projection='polar') >>> x = np.linspace(-np.pi, np.pi, 500) >>> vonmises_pdf = vonmises.pdf(x, loc=loc, kappa=kappa) >>> ticks = [0, 0.15, 0.3]
左圖包含笛卡爾圖。
>>> left.plot(x, vonmises_pdf) >>> left.set_yticks(ticks) >>> number_of_bins = int(np.sqrt(sample_size)) >>> left.hist(sample, density=True, bins=number_of_bins) >>> left.set_title("Cartesian plot") >>> left.set_xlim(-np.pi, np.pi) >>> left.grid(True)
右圖包含極座標圖。
>>> right.plot(x, vonmises_pdf, label="PDF") >>> right.set_yticks(ticks) >>> right.hist(sample, density=True, bins=number_of_bins, ... label="Histogram") >>> right.set_title("Polar plot") >>> right.legend(bbox_to_anchor=(0.15, 1.06))
方法
rvs(kappa, loc=0, scale=1, size=1, random_state=None)
隨機變數。
pdf(x, kappa, loc=0, scale=1)
機率密度函數。
logpdf(x, kappa, loc=0, scale=1)
機率密度函數的對數。
cdf(x, kappa, loc=0, scale=1)
累積分佈函數。
logcdf(x, kappa, loc=0, scale=1)
累積分佈函數的對數。
sf(x, kappa, loc=0, scale=1)
生存函數(也定義為
1 - cdf,但 sf 有時更準確)。logsf(x, kappa, loc=0, scale=1)
生存函數的對數。
ppf(q, kappa, loc=0, scale=1)
百分點函數(
cdf的反函數 — 百分位數)。isf(q, kappa, loc=0, scale=1)
反生存函數(
sf的反函數)。moment(order, kappa, loc=0, scale=1)
指定階數的非中心動差。
stats(kappa, loc=0, scale=1, moments=’mv’)
平均值 ('m')、變異數 ('v')、偏度 ('s') 和/或峰度 ('k')。
entropy(kappa, loc=0, scale=1)
RV 的(微分)熵。
fit(data)
通用資料的參數估計。有關關鍵字引數的詳細文件,請參閱 scipy.stats.rv_continuous.fit。
expect(func, args=(kappa,), loc=0, scale=1, lb=None, ub=None, conditional=False, **kwds)
函數(單一引數)關於分佈的期望值。
median(kappa, loc=0, scale=1)
分佈的中位數。
mean(kappa, loc=0, scale=1)
分佈的平均值。
var(kappa, loc=0, scale=1)
分佈的變異數。
std(kappa, loc=0, scale=1)
分佈的標準差。
interval(confidence, kappa, loc=0, scale=1)
中位數周圍等面積的信賴區間。