scipy.stats.vonmises_fisher#
- scipy.stats.vonmises_fisher = <scipy.stats._multivariate.vonmises_fisher_gen object>[來源]#
一個 von Mises-Fisher 變數。
mu關鍵字指定平均方向向量。kappa關鍵字指定集中參數。- 參數:
- muarray_like
分佈的平均方向。必須是範數為 1 的一維單位向量。
- kappafloat
集中參數。必須為正數。
- seed{None, int, np.random.RandomState, np.random.Generator}, optional
用於繪製隨機變數。如果
seed為None,則使用RandomState單例。如果seed為整數,則使用以 seed 為種子的新RandomState實例。如果seed已經是RandomState或Generator實例,則使用該物件。預設值為None。
另請參閱
scipy.stats.vonmises二維圓上的 Von-Mises Fisher 分佈
uniform_direction超球體表面上的均勻分佈
筆記
von Mises-Fisher 分佈是單位超球體表面上的方向分佈。單位向量 \(\mathbf{x}\) 的機率密度函數為
\[f(\mathbf{x}) = \frac{\kappa^{d/2-1}}{(2\pi)^{d/2}I_{d/2-1}(\kappa)} \exp\left(\kappa \mathbf{\mu}^T\mathbf{x}\right),\]其中 \(\mathbf{\mu}\) 是平均方向,\(\kappa\) 是集中參數,\(d\) 是維度,而 \(I\) 是第一類修正貝索函數。由於 \(\mu\) 代表方向,因此它必須是單位向量,或者換句話說,是超球體上的點:\(\mathbf{\mu}\in S^{d-1}\)。\(\kappa\) 是集中參數,這表示它必須為正數 (\(\kappa>0\)),並且分佈會隨著 \(\kappa\) 的增加而變得更窄。從這個意義上說,倒數值 \(1/\kappa\) 類似於常態分佈的變異數參數。
von Mises-Fisher 分佈通常用作球體上常態分佈的類比。直觀地說,對於單位向量,有用的距離度量由它們之間的角度 \(\alpha\) 給出。這正是 von Mises-Fisher 機率密度函數中純量積 \(\mathbf{\mu}^T\mathbf{x}=\cos(\alpha)\) 所描述的:平均方向 \(\mathbf{\mu}\) 和向量 \(\mathbf{x}\) 之間的角度。它們之間的角度越大,對於這個特定的平均方向 \(\mathbf{\mu}\),觀察到 \(\mathbf{x}\) 的機率就越小。
在維度 2 和 3 中,專門的演算法用於快速取樣 [2]、[3]。對於維度 4 或更高,則使用 [4] 中描述的拒絕取樣演算法。此實作部分基於 geomstats 套件 [5]、[6]。
在 1.11 版本中新增。
參考文獻
[1]Von Mises-Fisher 分佈,維基百科,https://en.wikipedia.org/wiki/Von_Mises%E2%80%93Fisher_distribution
[2]Mardia, K., and Jupp, P. 方向統計學。Wiley, 2000.
[3]J. Wenzel. S2 上 von Mises Fisher 分佈的數值穩定取樣。https://www.mitsuba-renderer.org/~wenzel/files/vmf.pdf
[4]Wood, A. von mises fisher 分佈的模擬。統計學通訊 - 模擬與計算 23, 1 (1994), 157-164. https://doi.org/10.1080/03610919408813161
[5]geomstats, Github。MIT 授權條款。存取日期:2023 年 1 月 6 日。geomstats/geomstats
[6]Miolane, N. et al. Geomstats:用於機器學習中黎曼幾何的 Python 套件。《機器學習研究期刊》21 (2020)。http://jmlr.org/papers/v21/19-027.html
範例
機率密度視覺化
繪製三維機率密度,以顯示隨集中參數增加的變化。密度由
pdf方法計算。>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from scipy.stats import vonmises_fisher >>> from matplotlib.colors import Normalize >>> n_grid = 100 >>> u = np.linspace(0, np.pi, n_grid) >>> v = np.linspace(0, 2 * np.pi, n_grid) >>> u_grid, v_grid = np.meshgrid(u, v) >>> vertices = np.stack([np.cos(v_grid) * np.sin(u_grid), ... np.sin(v_grid) * np.sin(u_grid), ... np.cos(u_grid)], ... axis=2) >>> x = np.outer(np.cos(v), np.sin(u)) >>> y = np.outer(np.sin(v), np.sin(u)) >>> z = np.outer(np.ones_like(u), np.cos(u)) >>> def plot_vmf_density(ax, x, y, z, vertices, mu, kappa): ... vmf = vonmises_fisher(mu, kappa) ... pdf_values = vmf.pdf(vertices) ... pdfnorm = Normalize(vmin=pdf_values.min(), vmax=pdf_values.max()) ... ax.plot_surface(x, y, z, rstride=1, cstride=1, ... facecolors=plt.cm.viridis(pdfnorm(pdf_values)), ... linewidth=0) ... ax.set_aspect('equal') ... ax.view_init(azim=-130, elev=0) ... ax.axis('off') ... ax.set_title(rf"$\kappa={kappa}$") >>> fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(9, 4), ... subplot_kw={"projection": "3d"}) >>> left, middle, right = axes >>> mu = np.array([-np.sqrt(0.5), -np.sqrt(0.5), 0]) >>> plot_vmf_density(left, x, y, z, vertices, mu, 5) >>> plot_vmf_density(middle, x, y, z, vertices, mu, 20) >>> plot_vmf_density(right, x, y, z, vertices, mu, 100) >>> plt.subplots_adjust(top=1, bottom=0.0, left=0.0, right=1.0, wspace=0.) >>> plt.show()

隨著集中參數增加,點會更緊密地聚集在平均方向周圍。
抽樣
使用
rvs方法從分佈中抽取 5 個樣本,產生一個 5x3 陣列。>>> rng = np.random.default_rng() >>> mu = np.array([0, 0, 1]) >>> samples = vonmises_fisher(mu, 20).rvs(5, random_state=rng) >>> samples array([[ 0.3884594 , -0.32482588, 0.86231516], [ 0.00611366, -0.09878289, 0.99509023], [-0.04154772, -0.01637135, 0.99900239], [-0.14613735, 0.12553507, 0.98126695], [-0.04429884, -0.23474054, 0.97104814]])
這些樣本是球體 \(S^2\) 上的單位向量。為了驗證,讓我們計算它們的歐幾里得範數
>>> np.linalg.norm(samples, axis=1) array([1., 1., 1., 1., 1.])
繪製從 von Mises-Fisher 分佈中抽取的 20 個觀測值,以顯示隨集中參數 \(\kappa\) 增加的變化。紅點突顯平均方向 \(\mu\)。
>>> def plot_vmf_samples(ax, x, y, z, mu, kappa): ... vmf = vonmises_fisher(mu, kappa) ... samples = vmf.rvs(20) ... ax.plot_surface(x, y, z, rstride=1, cstride=1, linewidth=0, ... alpha=0.2) ... ax.scatter(samples[:, 0], samples[:, 1], samples[:, 2], c='k', s=5) ... ax.scatter(mu[0], mu[1], mu[2], c='r', s=30) ... ax.set_aspect('equal') ... ax.view_init(azim=-130, elev=0) ... ax.axis('off') ... ax.set_title(rf"$\kappa={kappa}$") >>> mu = np.array([-np.sqrt(0.5), -np.sqrt(0.5), 0]) >>> fig, axes = plt.subplots(nrows=1, ncols=3, ... subplot_kw={"projection": "3d"}, ... figsize=(9, 4)) >>> left, middle, right = axes >>> plot_vmf_samples(left, x, y, z, mu, 5) >>> plot_vmf_samples(middle, x, y, z, mu, 20) >>> plot_vmf_samples(right, x, y, z, mu, 100) >>> plt.subplots_adjust(top=1, bottom=0.0, left=0.0, ... right=1.0, wspace=0.) >>> plt.show()
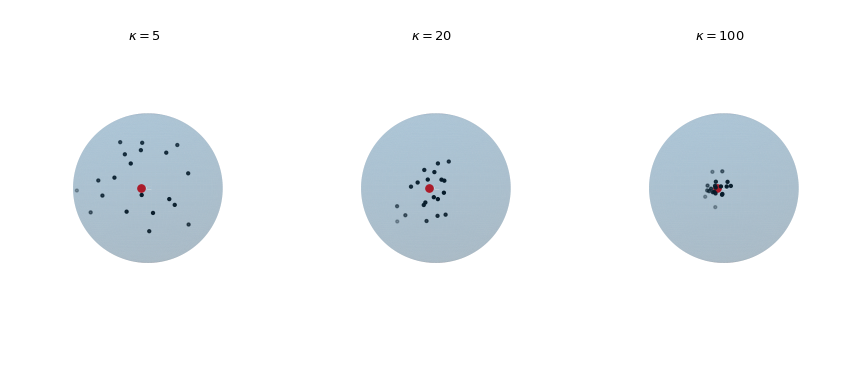
圖表顯示,隨著集中參數 \(\kappa\) 增加,產生的樣本更緊密地集中在平均方向周圍。
擬合分佈參數
可以使用
fit方法將分佈擬合到資料,並傳回估計的參數。作為一個玩具範例,讓我們將分佈擬合到從已知的 von Mises-Fisher 分佈中抽取的樣本。>>> mu, kappa = np.array([0, 0, 1]), 20 >>> samples = vonmises_fisher(mu, kappa).rvs(1000, random_state=rng) >>> mu_fit, kappa_fit = vonmises_fisher.fit(samples) >>> mu_fit, kappa_fit (array([0.01126519, 0.01044501, 0.99988199]), 19.306398751730995)
我們看到估計的參數
mu_fit和kappa_fit非常接近真實參數。方法
pdf(x, mu=None, kappa=1)
機率密度函數。
logpdf(x, mu=None, kappa=1)
機率密度函數的對數。
rvs(mu=None, kappa=1, size=1, random_state=None)
從 von Mises-Fisher 分佈中抽取隨機樣本。
entropy(mu=None, kappa=1)
計算 von Mises-Fisher 分佈的微分熵。
fit(data)
將 von Mises-Fisher 分佈擬合到資料。