scipy.stats.normal_inverse_gamma#
- scipy.stats.normal_inverse_gamma = <scipy.stats._multivariate.normal_inverse_gamma_gen object>[來源]#
常態-逆伽瑪分布。
常態-逆伽瑪分布是具有未知平均數和變異數的常態分布的共軛先驗分布。
- 參數:
- mu, lmbda, a, barray_like
分布的形狀參數。請參閱註釋。
- seed{None, int, np.random.RandomState, np.random.Generator}, optional
用於繪製隨機變數。如果 seed 為 None,則使用 RandomState 單例。如果 seed 為整數,則使用新的
RandomState實例,並以 seed 作為種子。如果 seed 已經是RandomState或Generator實例,則使用該物件。預設值為 None。
註釋
normal_inverse_gamma的機率密度函數為\[f(x, \sigma^2; \mu, \lambda, \alpha, \beta) = \frac{\sqrt{\lambda}}{\sqrt{2 \pi \sigma^2}} \frac{\beta^\alpha}{\Gamma(\alpha)} \left( \frac{1}{\sigma^2} \right)^{\alpha + 1} \exp \left(- \frac{2 \beta + \lambda (x - \mu)^2} {2 \sigma^2} \right)\]其中所有參數都是實數且有限,且 \(\sigma^2 > 0\)、 \(\lambda > 0\)、 \(\alpha > 0\) 和 \(\beta > 0\)。
方法
normal_inverse_gamma.pdf和normal_inverse_gamma.logpdf接受 x 和 s2 作為引數 \(x\) 和 \(\sigma^2\)。所有方法都接受 mu、 lmbda、 a 和 b 作為形狀參數 \(\mu\)、 \(\lambda\)、 \(\alpha\) 和 \(\beta\)。在版本 1.15 中新增。
參考文獻
[1]Normal-inverse-gamma distribution, Wikipedia, https://en.wikipedia.org/wiki/Normal-inverse-gamma_distribution
範例
假設我們希望研究常態-逆伽瑪分布與逆伽瑪分布之間的關係。
>>> import numpy as np >>> from scipy import stats >>> import matplotlib.pyplot as plt >>> rng = np.random.default_rng() >>> mu, lmbda, a, b = 0, 1, 20, 20 >>> norm_inv_gamma = stats.normal_inverse_gamma(mu, lmbda, a, b) >>> inv_gamma = stats.invgamma(a, scale=b)
一種方法是將隨機變數的 s2 元素的分布與逆伽瑪分布的 PDF 進行比較。
>>> _, s2 = norm_inv_gamma.rvs(size=10000, random_state=rng) >>> bins = np.linspace(s2.min(), s2.max(), 50) >>> plt.hist(s2, bins=bins, density=True, label='Frequency density') >>> s2 = np.linspace(s2.min(), s2.max(), 300) >>> plt.plot(s2, inv_gamma.pdf(s2), label='PDF') >>> plt.xlabel(r'$\sigma^2$') >>> plt.ylabel('Frequency density / PMF') >>> plt.show()
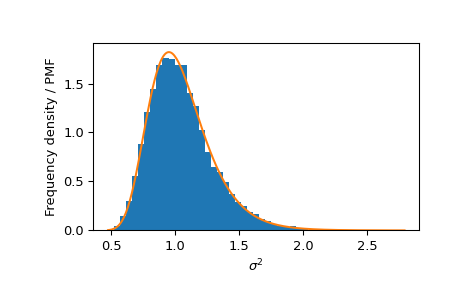
同樣地,我們可以將 s2 的邊際分布與逆伽瑪分布進行比較。
>>> from scipy.integrate import quad_vec >>> from scipy import integrate >>> s2 = np.linspace(0.5, 3, 6) >>> res = quad_vec(lambda x: norm_inv_gamma.pdf(x, s2), -np.inf, np.inf)[0] >>> np.allclose(res, inv_gamma.pdf(s2)) True
樣本平均值可與分布的平均值相比較。
>>> x, s2 = norm_inv_gamma.rvs(size=10000, random_state=rng) >>> x.mean(), s2.mean() (np.float64(-0.005254750127304425), np.float64(1.050438111436508)) >>> norm_inv_gamma.mean() (np.float64(0.0), np.float64(1.0526315789473684))
同樣地,對於變異數
>>> x.var(ddof=1), s2.var(ddof=1) (np.float64(1.0546150578185023), np.float64(0.061829865266330754)) >>> norm_inv_gamma.var() (np.float64(1.0526315789473684), np.float64(0.061557402277623886))
方法
pdf(x, s2, mu=0, lmbda=1, a=1, b=1)
機率密度函數。
logpdf(x, s2, mu=0, lmbda=1, a=1, b=1)
機率密度函數的對數。
mean(mu=0, lmbda=1, a=1, b=1)
分布平均值。
var(mu=0, lmbda=1, a=1, b=1)
分布變異數。
rvs(mu=0, lmbda=1, a=1, b=1, size=None, random_state=None)
繪製隨機樣本。