scipy.special.fdtri#
- scipy.special.fdtri(dfn, dfd, p, out=None) = <ufunc 'fdtri'>#
F 分佈的第 p 個分位數。
此函數是 F 分佈 CDF 的反函數,
fdtr,傳回 x 使得 fdtr(dfn, dfd, x) = p。- 參數:
- dfnarray_like
第一個參數(正浮點數)。
- dfdarray_like
第二個參數(正浮點數)。
- parray_like
累積機率,在 [0, 1] 範圍內。
- outndarray, optional
函數值的選用輸出陣列
- 返回:
- xscalar 或 ndarray
對應於 p 的分位數。
參見
fdtrF 分佈累積分佈函數
fdtrcF 分佈存活函數
scipy.stats.fF 分佈
註解
此計算使用與不完全貝塔反函數 \(I^{-1}_x(a, b)\) 的關係進行。令 \(z = I^{-1}_p(d_d/2, d_n/2).\) 則,
\[x = \frac{d_d (1 - z)}{d_n z}.\]如果 p 使得 \(x < 0.5\),則改用以下關係以提高穩定性:令 \(z' = I^{-1}_{1 - p}(d_n/2, d_d/2).\) 則,
\[x = \frac{d_d z'}{d_n (1 - z')}.\]F 分佈也可作為
scipy.stats.f使用。直接呼叫fdtri可以比呼叫scipy.stats.f的ppf方法提高效能(請參閱下面的最後一個範例)。參考文獻
[1]Cephes Mathematical Functions Library, http://www.netlib.org/cephes/
範例
fdtri代表 F 分佈 CDF 的反函數,該函數可作為fdtr使用。在這裡,我們計算df1=1、df2=2在x=3時的 CDF。fdtri接著在給定 df1、df2 和計算出的 CDF 值時傳回3。>>> import numpy as np >>> from scipy.special import fdtri, fdtr >>> df1, df2 = 1, 2 >>> x = 3 >>> cdf_value = fdtr(df1, df2, x) >>> fdtri(df1, df2, cdf_value) 3.000000000000006
透過為 x 提供 NumPy 陣列,在多個點計算函數。
>>> x = np.array([0.1, 0.4, 0.7]) >>> fdtri(1, 2, x) array([0.02020202, 0.38095238, 1.92156863])
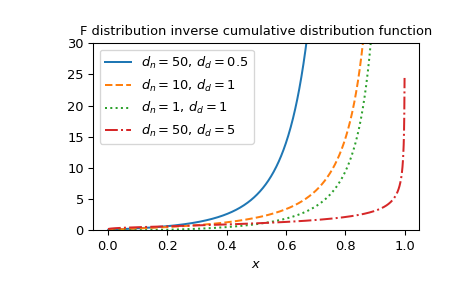
繪製多個參數集的函數圖。
>>> import matplotlib.pyplot as plt >>> dfn_parameters = [50, 10, 1, 50] >>> dfd_parameters = [0.5, 1, 1, 5] >>> linestyles = ['solid', 'dashed', 'dotted', 'dashdot'] >>> parameters_list = list(zip(dfn_parameters, dfd_parameters, ... linestyles)) >>> x = np.linspace(0, 1, 1000) >>> fig, ax = plt.subplots() >>> for parameter_set in parameters_list: ... dfn, dfd, style = parameter_set ... fdtri_vals = fdtri(dfn, dfd, x) ... ax.plot(x, fdtri_vals, label=rf"$d_n={dfn},\, d_d={dfd}$", ... ls=style) >>> ax.legend() >>> ax.set_xlabel("$x$") >>> title = "F distribution inverse cumulative distribution function" >>> ax.set_title(title) >>> ax.set_ylim(0, 30) >>> plt.show()
F 分佈也可作為
scipy.stats.f使用。直接使用fdtri可能比呼叫scipy.stats.f的ppf方法快得多,特別是對於小型陣列或個別值。若要獲得相同的結果,必須使用以下參數化:stats.f(dfn, dfd).ppf(x)=fdtri(dfn, dfd, x)。>>> from scipy.stats import f >>> dfn, dfd = 1, 2 >>> x = 0.7 >>> fdtri_res = fdtri(dfn, dfd, x) # this will often be faster than below >>> f_dist_res = f(dfn, dfd).ppf(x) >>> f_dist_res == fdtri_res # test that results are equal True