scipy.stats.
yeojohnson_llf#
- scipy.stats.yeojohnson_llf(lmb, data)[原始碼]#
Yeo-Johnson 對數概似函數。
- 參數:
- lmb純量
Yeo-Johnson 轉換的參數。參見
yeojohnson以了解詳細資訊。- dataarray_like
用於計算 Yeo-Johnson 對數概似的資料。如果 data 是多維的,則沿著第一個軸計算對數概似。
- 回傳值:
- llffloat
給定 lmb 的 data 的 Yeo-Johnson 對數概似。
註解
Yeo-Johnson 對數概似函數在此定義為
\[llf = -N/2 \log(\hat{\sigma}^2) + (\lambda - 1) \sum_i \text{ sign }(x_i)\log(|x_i| + 1)\]其中 \(\hat{\sigma}^2\) 是 Yeo-Johnson 轉換後的輸入資料
x的估計變異數。在 1.2.0 版本中新增。
範例
>>> import numpy as np >>> from scipy import stats >>> import matplotlib.pyplot as plt >>> from mpl_toolkits.axes_grid1.inset_locator import inset_axes
產生一些隨機變數,並針對一系列
lmbda值計算它們的 Yeo-Johnson 對數概似值>>> x = stats.loggamma.rvs(5, loc=10, size=1000) >>> lmbdas = np.linspace(-2, 10) >>> llf = np.zeros(lmbdas.shape, dtype=float) >>> for ii, lmbda in enumerate(lmbdas): ... llf[ii] = stats.yeojohnson_llf(lmbda, x)
也使用
yeojohnson找到最佳 lmbda 值>>> x_most_normal, lmbda_optimal = stats.yeojohnson(x)
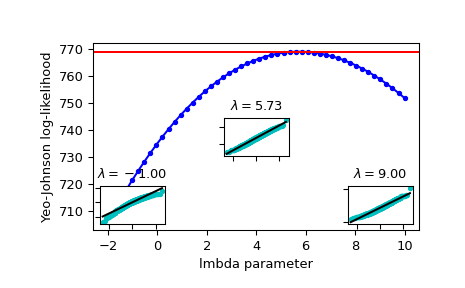
繪製對數概似值作為 lmbda 的函數。新增最佳 lmbda 作為水平線,以檢查它是否真的是最佳值
>>> fig = plt.figure() >>> ax = fig.add_subplot(111) >>> ax.plot(lmbdas, llf, 'b.-') >>> ax.axhline(stats.yeojohnson_llf(lmbda_optimal, x), color='r') >>> ax.set_xlabel('lmbda parameter') >>> ax.set_ylabel('Yeo-Johnson log-likelihood')
現在新增一些機率圖,以顯示在對數概似值最大化的地方,使用
yeojohnson轉換後的資料看起來最接近常態分佈>>> locs = [3, 10, 4] # 'lower left', 'center', 'lower right' >>> for lmbda, loc in zip([-1, lmbda_optimal, 9], locs): ... xt = stats.yeojohnson(x, lmbda=lmbda) ... (osm, osr), (slope, intercept, r_sq) = stats.probplot(xt) ... ax_inset = inset_axes(ax, width="20%", height="20%", loc=loc) ... ax_inset.plot(osm, osr, 'c.', osm, slope*osm + intercept, 'k-') ... ax_inset.set_xticklabels([]) ... ax_inset.set_yticklabels([]) ... ax_inset.set_title(r'$\lambda=%1.2f$' % lmbda)
>>> plt.show()