power#
- scipy.stats.power(test, rvs, n_observations, *, significance=0.01, vectorized=None, n_resamples=10000, batch=None, kwargs=None)[原始碼]#
模擬在對立假設下假設檢定的檢定力。
- 參數:
- testcallable
要模擬檢定力的假設檢定。
test必須是一個可呼叫物件,它接受一個樣本 (例如test(sample)) 或len(rvs)個獨立樣本 (例如,如果 rvs 包含兩個可呼叫物件且 n_observations 包含兩個值,則為test(samples1, sample2)),並傳回檢定的 p 值。如果 vectorized 設定為True,則test也必須接受關鍵字引數 axis,並且要向量化以沿著樣本的提供的 axis 執行檢定。scipy.stats中任何具有 axis 引數並傳回具有 pvalue 屬性物件的可呼叫物件也是可接受的。- rvscallable 或 callables 的元組
在對立假設下產生隨機變數的可呼叫物件或可呼叫物件序列。rvs 的每個元素都必須接受關鍵字引數
size(例如rvs(size=(m, n))) 並傳回該形狀的 N 維陣列。如果 rvs 是一個序列,則 rvs 中可呼叫物件的數量必須與 n_observations 的元素數量相符,即len(rvs) == len(n_observations)。如果 rvs 是單個可呼叫物件,則 n_observations 會被視為單個元素。- n_observations整數元組或整數陣列元組
如果是一系列整數,則每個整數都是要傳遞給
test的樣本大小。如果是一系列整數陣列,則會針對每組對應的樣本大小模擬檢定力。請參閱範例。- significance浮點數或類陣列浮點數,預設值:0.01
顯著性閾值;也就是說,p 值低於此值時,假設檢定結果將被視為反對虛無假設的證據。等效地,在虛無假設下可接受的第一型錯誤率。如果是陣列,則會針對每個顯著性閾值模擬檢定力。
- kwargsdict,選用
要傳遞給 rvs 和/或
test可呼叫物件的關鍵字引數。內省用於判斷哪些關鍵字引數可以傳遞給每個可呼叫物件。與每個關鍵字對應的值必須是陣列。陣列必須可以彼此廣播,並且可以與 n_observations 中的每個陣列廣播。針對每組對應的樣本大小和引數模擬檢定力。請參閱範例。- vectorizedbool,選用
如果 vectorized 設定為
False,則不會將關鍵字引數 axis 傳遞給test,並且預期僅針對 1D 樣本執行檢定。如果為True,則會將關鍵字引數 axis 傳遞給test,並且預期在傳遞 N 維樣本陣列時沿著 axis 執行檢定。如果為None(預設值),如果axis是test的參數,則 vectorized 將設定為True。使用向量化檢定通常可以減少計算時間。- n_resamplesint,預設值:10000
從 rvs 的每個可呼叫物件中抽取的樣本數。等效地,在對立假設下執行的檢定數,以近似檢定力。
- batchint,選用
每次呼叫
test時要處理的樣本數。記憶體使用量與 batch 和最大樣本大小的乘積成正比。預設值為None,在這種情況下,batch 等於 n_resamples。
- 傳回值:
- resPowerResult
具有以下屬性的物件
- powerfloat 或 ndarray
針對對立假設的估計檢定力。
- pvaluesndarray
在對立假設下觀察到的 p 值。
註解
檢定力模擬如下
在 rvs 指定的對立假設下,抽取許多隨機樣本 (或樣本集),每個樣本的大小由 n_observations 指定。
對於每個樣本 (或樣本集),根據
test計算 p 值。這些 p 值記錄在結果物件的pvalues屬性中。計算小於 significance 水準的 p 值比例。這是記錄在結果物件的
power屬性中的檢定力。
假設 significance 是一個形狀為
shape1的陣列,kwargs 和 n_observations 的元素可以互相廣播到形狀shape2,並且test傳回形狀為shape3的 p 值陣列。那麼結果物件power屬性的形狀將為shape1 + shape2 + shape3,而pvalues屬性的形狀將為shape2 + shape3 + (n_resamples,)。範例
假設我們希望在以下條件下模擬獨立樣本 t 檢定的檢定力
第一個樣本有 10 個觀測值,取自平均值為 0 的常態分佈。
第二個樣本有 12 個觀測值,取自平均值為 1.0 的常態分佈。
顯著性的 p 值閾值為 0.05。
>>> import numpy as np >>> from scipy import stats >>> rng = np.random.default_rng() >>> >>> test = stats.ttest_ind >>> n_observations = (10, 12) >>> rvs1 = rng.normal >>> rvs2 = lambda size: rng.normal(loc=1, size=size) >>> rvs = (rvs1, rvs2) >>> res = stats.power(test, rvs, n_observations, significance=0.05) >>> res.power 0.6116
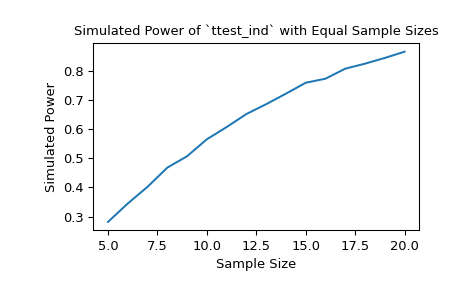
對於大小分別為 10 和 12 的樣本,在選定的對立假設下,顯著性閾值為 0.05 的 t 檢定的檢定力約為 60%。我們可以透過傳遞樣本大小陣列來研究樣本大小對檢定力的影響。
>>> import matplotlib.pyplot as plt >>> nobs_x = np.arange(5, 21) >>> nobs_y = nobs_x >>> n_observations = (nobs_x, nobs_y) >>> res = stats.power(test, rvs, n_observations, significance=0.05) >>> ax = plt.subplot() >>> ax.plot(nobs_x, res.power) >>> ax.set_xlabel('Sample Size') >>> ax.set_ylabel('Simulated Power') >>> ax.set_title('Simulated Power of `ttest_ind` with Equal Sample Sizes') >>> plt.show()
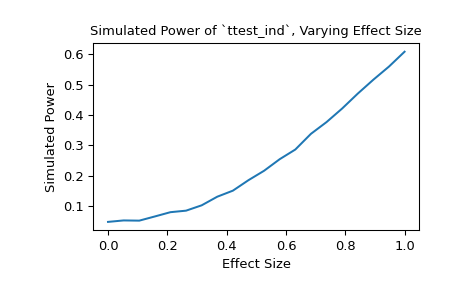
或者,我們可以研究效應大小對檢定力的影響。在這種情況下,效應大小是第二個樣本基礎分佈的位置。
>>> n_observations = (10, 12) >>> loc = np.linspace(0, 1, 20) >>> rvs2 = lambda size, loc: rng.normal(loc=loc, size=size) >>> rvs = (rvs1, rvs2) >>> res = stats.power(test, rvs, n_observations, significance=0.05, ... kwargs={'loc': loc}) >>> ax = plt.subplot() >>> ax.plot(loc, res.power) >>> ax.set_xlabel('Effect Size') >>> ax.set_ylabel('Simulated Power') >>> ax.set_title('Simulated Power of `ttest_ind`, Varying Effect Size') >>> plt.show()
我們也可以使用
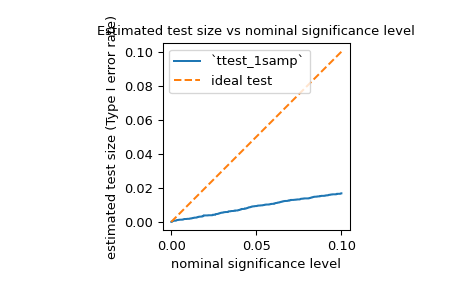
power來估計檢定的第一型錯誤率 (也稱為含糊不清的術語「大小」),並評估它是否與名義水準相符。例如,jarque_bera的虛無假設是樣本取自與常態分佈具有相同偏度和峰度的分佈。為了估計第一型錯誤率,我們可以將虛無假設視為真實的對立假設並計算檢定力。>>> test = stats.jarque_bera >>> n_observations = 10 >>> rvs = rng.normal >>> significance = np.linspace(0.0001, 0.1, 1000) >>> res = stats.power(test, rvs, n_observations, significance=significance) >>> size = res.power
如下所示,如其文件中所述,對於如此小的樣本,檢定的第一型錯誤率遠低於名義水準。
>>> ax = plt.subplot() >>> ax.plot(significance, size) >>> ax.plot([0, 0.1], [0, 0.1], '--') >>> ax.set_xlabel('nominal significance level') >>> ax.set_ylabel('estimated test size (Type I error rate)') >>> ax.set_title('Estimated test size vs nominal significance level') >>> ax.set_aspect('equal', 'box') >>> ax.legend(('`ttest_1samp`', 'ideal test')) >>> plt.show()
正如人們可能從如此保守的檢定中預期的那樣,對於某些對立假設,檢定力非常低。例如,在樣本取自 Laplace 分佈的對立假設下,檢定的檢定力可能不會比第一型錯誤率高出多少。
>>> rvs = rng.laplace >>> significance = np.linspace(0.0001, 0.1, 1000) >>> res = stats.power(test, rvs, n_observations, significance=0.05) >>> print(res.power) 0.0587
這不是 SciPy 實作中的錯誤;這僅僅是因為檢定統計量的虛無分佈是在樣本大小很大 (即趨近於無窮大) 的假設下推導出來的,並且這種漸近近似對於小樣本來說並不準確。在這種情況下,重新取樣和蒙地卡羅方法 (例如
permutation_test、goodness_of_fit、monte_carlo_test) 可能更適合。