kurtosis#
- scipy.stats.kurtosis(a, axis=0, fisher=True, bias=True, nan_policy='propagate', *, keepdims=False)[原始碼]#
計算資料集的峰度(費雪或皮爾森)。
峰度是第四個中心動差除以變異數的平方。如果使用費雪定義,則從結果中減去 3.0,使常態分佈的值為 0.0。
如果 bias 為 False,則峰度的計算會使用 k 統計量來消除來自偏差動差估計器的偏差
使用
kurtosistest來查看結果是否夠接近常態分佈。- 參數:
- a陣列
計算峰度的資料。
- axisint 或 None,預設值:0
如果為整數,則為輸入的軸,沿著該軸計算統計量。輸入的每個軸切片(例如,列)的統計量將出現在輸出的對應元素中。如果
None,則在計算統計量之前,輸入將被展平。- fisherbool,選用
如果為 True,則使用費雪定義(常態 ==> 0.0)。如果為 False,則使用皮爾森定義(常態 ==> 3.0)。
- biasbool,選用
如果為 False,則計算會針對統計偏差進行校正。
- nan_policy{‘propagate’, ‘omit’, ‘raise’}
定義如何處理輸入的 NaN。
propagate:如果在計算統計量的軸切片(例如,列)中存在 NaN,則輸出的對應條目將為 NaN。omit:執行計算時將省略 NaN。如果沿著計算統計量的軸切片中剩餘的資料不足,則輸出的對應條目將為 NaN。raise:如果存在 NaN,將引發ValueError。
- keepdimsbool,預設值:False
如果設定為 True,則縮減的軸將保留在結果中,作為大小為一的維度。使用此選項,結果將正確地與輸入陣列進行廣播。
- 回傳值:
- kurtosis陣列
沿軸的值的峰度,在所有值都相等時回傳 NaN。
註解
從 SciPy 1.9 開始,
np.matrix輸入(不建議用於新程式碼)會在執行計算之前轉換為np.ndarray。在這種情況下,輸出將是純量或形狀適當的np.ndarray,而不是 2Dnp.matrix。同樣地,雖然會忽略遮罩陣列的遮罩元素,但輸出將是純量或np.ndarray,而不是mask=False的遮罩陣列。參考文獻
[1]Zwillinger, D. and Kokoska, S. (2000). CRC Standard Probability and Statistics Tables and Formulae. Chapman & Hall: New York. 2000.
範例
在費雪定義中,常態分佈的峰度為零。在以下範例中,峰度接近於零,因為它是從資料集計算出來的,而不是從連續分佈計算出來的。
>>> import numpy as np >>> from scipy.stats import norm, kurtosis >>> data = norm.rvs(size=1000, random_state=3) >>> kurtosis(data) -0.06928694200380558
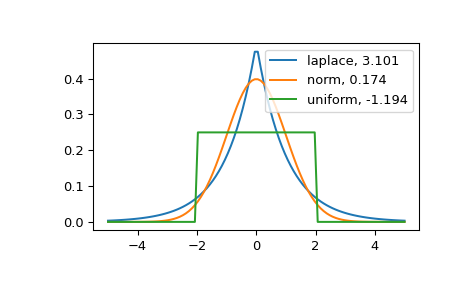
峰度較高的分佈具有較重的尾部。費雪定義中常態分佈的零值峰度可以作為參考點。
>>> import matplotlib.pyplot as plt >>> import scipy.stats as stats >>> from scipy.stats import kurtosis
>>> x = np.linspace(-5, 5, 100) >>> ax = plt.subplot() >>> distnames = ['laplace', 'norm', 'uniform']
>>> for distname in distnames: ... if distname == 'uniform': ... dist = getattr(stats, distname)(loc=-2, scale=4) ... else: ... dist = getattr(stats, distname) ... data = dist.rvs(size=1000) ... kur = kurtosis(data, fisher=True) ... y = dist.pdf(x) ... ax.plot(x, y, label="{}, {}".format(distname, round(kur, 3))) ... ax.legend()
拉普拉斯分佈比常態分佈具有更重的尾部。均勻分佈(具有負峰度)具有最薄的尾部。