gaussian_kde#
- class scipy.stats.gaussian_kde(dataset, bw_method=None, weights=None)[source]#
使用高斯核的核密度估計表示。
核密度估計是一種以非參數方式估計隨機變數的機率密度函數 (PDF) 的方法。
gaussian_kde適用於單變量和多變量數據。它包含自動頻寬確定功能。此估計最適用於單峰分佈;雙峰或多峰分佈往往會被過度平滑。- 參數:
- datasetarray_like
用於估計的數據點。在單變量數據的情況下,這是一個 1 維陣列,否則是一個形狀為 (# of dims, # of data) 的 2 維陣列。
- bw_methodstr, scalar 或 callable, optional
用於計算估計器頻寬的方法。這可以是 ‘scott’、‘silverman’、純量常數或可呼叫物件。如果為純量,這將直接用作 kde.factor。如果為可呼叫物件,它應該將
gaussian_kde實例作為唯一參數,並返回一個純量。如果為 None (預設值),則使用 ‘scott’。有關更多詳細資訊,請參閱「說明」。- weightsarray_like, optional
數據點的權重。這必須與數據集具有相同的形狀。如果為 None (預設值),則假設樣本具有相同的權重
說明
頻寬選擇強烈影響從 KDE 獲得的估計值 (比核的實際形狀影響更大)。頻寬選擇可以通過「經驗法則」、交叉驗證、「插入方法」或其他方式完成;請參閱 [3]、[4] 以獲取評論。
gaussian_kde使用經驗法則,預設值為 Scott 法則。Scott 法則 [1],實作為
scotts_factor,是n**(-1./(d+4)),
其中
n是數據點的數量,d是維度的數量。在不等權重點的情況下,scotts_factor變為neff**(-1./(d+4)),
其中
neff是有效數據點的數量。Silverman 法則 [2],實作為silverman_factor,是(n * (d + 2) / 4.)**(-1. / (d + 4)).
或者在不等權重點的情況下
(neff * (d + 2) / 4.)**(-1. / (d + 4)).
核密度估計的良好一般描述可以在 [1] 和 [2] 中找到,這種多維實作的數學原理可以在 [1] 中找到。
對於一組加權樣本,有效數據點的數量
neff由下式定義neff = sum(weights)^2 / sum(weights^2)
如 [5] 中詳細說明。
gaussian_kde目前不支援位於其表示空間的較低維度子空間中的數據。對於此類數據,請考慮執行主成分分析/降維,並將gaussian_kde與轉換後的數據一起使用。參考文獻
[1] (1,2,3)D.W. Scott, “Multivariate Density Estimation: Theory, Practice, and Visualization”, John Wiley & Sons, New York, Chicester, 1992.
[2] (1,2)B.W. Silverman, “Density Estimation for Statistics and Data Analysis”, Vol. 26, Monographs on Statistics and Applied Probability, Chapman and Hall, London, 1986.
[3]B.A. Turlach, “Bandwidth Selection in Kernel Density Estimation: A Review”, CORE and Institut de Statistique, Vol. 19, pp. 1-33, 1993.
[4]D.M. Bashtannyk and R.J. Hyndman, “Bandwidth selection for kernel conditional density estimation”, Computational Statistics & Data Analysis, Vol. 36, pp. 279-298, 2001.
[5]Gray P. G., 1969, Journal of the Royal Statistical Society. Series A (General), 132, 272
範例
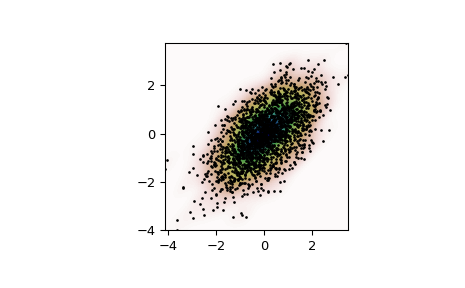
產生一些隨機二維數據
>>> import numpy as np >>> from scipy import stats >>> def measure(n): ... "Measurement model, return two coupled measurements." ... m1 = np.random.normal(size=n) ... m2 = np.random.normal(scale=0.5, size=n) ... return m1+m2, m1-m2
>>> m1, m2 = measure(2000) >>> xmin = m1.min() >>> xmax = m1.max() >>> ymin = m2.min() >>> ymax = m2.max()
對數據執行核密度估計
>>> X, Y = np.mgrid[xmin:xmax:100j, ymin:ymax:100j] >>> positions = np.vstack([X.ravel(), Y.ravel()]) >>> values = np.vstack([m1, m2]) >>> kernel = stats.gaussian_kde(values) >>> Z = np.reshape(kernel(positions).T, X.shape)
繪製結果
>>> import matplotlib.pyplot as plt >>> fig, ax = plt.subplots() >>> ax.imshow(np.rot90(Z), cmap=plt.cm.gist_earth_r, ... extent=[xmin, xmax, ymin, ymax]) >>> ax.plot(m1, m2, 'k.', markersize=2) >>> ax.set_xlim([xmin, xmax]) >>> ax.set_ylim([ymin, ymax]) >>> plt.show()
- 屬性:
- datasetndarray
初始化
gaussian_kde時使用的數據集。- dint
維度數量。
- nint
數據點數量。
- neffint
有效數據點數量。
在 1.2.0 版本中新增。
- factorfloat
頻寬因子,從 kde.covariance_factor 取得。kde.factor 的平方乘以 kde 估計中的數據共變異數矩陣。
- covariancendarray
dataset 的共變異數矩陣,按計算出的頻寬 (kde.factor) 縮放。
- inv_covndarray
covariance 的逆矩陣。
方法
evaluate(points)在一組點上評估估計的 pdf。
__call__(points)在一組點上評估估計的 pdf。
integrate_gaussian(mean, cov)將估計密度乘以多元高斯分佈,並在整個空間上積分。
integrate_box_1d(low, high)計算 1D pdf 在兩個邊界之間的積分。
integrate_box(low_bounds, high_bounds[, maxpts])計算 pdf 在矩形區間上的積分。
integrate_kde(other)計算此核密度估計與另一個核密度估計乘積的積分。
pdf(x)在提供的點集上評估估計的 pdf。
logpdf(x)在提供的點集上評估估計的 pdf 的對數。
resample([size, seed])從估計的 pdf 中隨機取樣數據集。
set_bandwidth([bw_method])使用給定方法計算估計器頻寬。
計算乘以數據共變異數矩陣以獲得核共變異數矩陣的係數 (kde.factor)。