機率分佈#
SciPy 有兩種基礎架構用於處理機率分佈。本教學適用於較舊的一種,它有許多預定義的分佈;然而,新的基礎架構可以用於這些分佈中的大多數,並且具有許多優點。對於新的基礎架構,請參閱 隨機變數轉換指南。
已經實作了兩個通用分佈類別,用於封裝連續隨機變數和離散隨機變數。已經使用這些類別實作了超過 100 個連續隨機變數 (RV) 和 20 個離散隨機變數。有關個別分佈的數學參考資訊,請參閱連續統計分佈和離散統計分佈。
所有統計函數都位於子套件 scipy.stats 中,並且也可以從 stats 子套件的 docstring 中獲得這些函數和可用隨機變數的相當完整的列表。
在下面的討論中,我們主要關注連續 RV。幾乎所有內容也適用於離散變數,但我們在此處指出一些差異:離散分佈的特定點。
在下面的程式碼範例中,我們假設 scipy.stats 套件匯入為
>>> from scipy import stats
並且在某些情況下,我們假設個別物件匯入為
>>> from scipy.stats import norm
取得協助#
首先,所有分佈都附帶協助函數。要僅取得一些基本資訊,我們列印相關的 docstring:print(stats.norm.__doc__)。
要查找支援,即分佈的上限和下限,請呼叫
>>> print('bounds of distribution lower: %s, upper: %s' % norm.support())
bounds of distribution lower: -inf, upper: inf
我們可以使用 dir(norm) 列出分佈的所有方法和屬性。事實證明,有些方法是私有的,儘管它們並未如此命名(它們的名稱不是以底線開頭),例如 veccdf,僅適用於內部計算(當有人嘗試使用這些方法時,它們會發出警告,並將在稍後移除)。
要取得真正的主要方法,我們列出凍結分佈的方法。(我們在下面解釋 凍結 分佈的含義)。
>>> rv = norm()
>>> dir(rv) # reformatted
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__gt__', '__hash__',
'__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__',
'__str__', '__subclasshook__', '__weakref__', 'a', 'args', 'b', 'cdf',
'dist', 'entropy', 'expect', 'interval', 'isf', 'kwds', 'logcdf',
'logpdf', 'logpmf', 'logsf', 'mean', 'median', 'moment', 'pdf', 'pmf',
'ppf', 'random_state', 'rvs', 'sf', 'stats', 'std', 'var']
最後,我們可以透過內省取得可用分佈的列表
>>> dist_continu = [d for d in dir(stats) if
... isinstance(getattr(stats, d), stats.rv_continuous)]
>>> dist_discrete = [d for d in dir(stats) if
... isinstance(getattr(stats, d), stats.rv_discrete)]
>>> print('number of continuous distributions: %d' % len(dist_continu))
number of continuous distributions: 109
>>> print('number of discrete distributions: %d' % len(dist_discrete))
number of discrete distributions: 21
常用方法#
連續 RV 的主要公用方法是
rvs:隨機變量
pdf:機率密度函數
cdf:累積分佈函數
sf:生存函數 (1-CDF)
ppf:百分點函數(CDF 的反函數)
isf:反生存函數(SF 的反函數)
stats:傳回平均值、變異數、(費雪)偏度或(費雪)峰度
moment:分佈的非中心動差
讓我們以常態 RV 為例。
>>> norm.cdf(0)
0.5
要計算多個點的 cdf,我們可以傳遞列表或 numpy 陣列。
>>> norm.cdf([-1., 0, 1])
array([ 0.15865525, 0.5, 0.84134475])
>>> import numpy as np
>>> norm.cdf(np.array([-1., 0, 1]))
array([ 0.15865525, 0.5, 0.84134475])
因此,基本方法,例如 pdf、cdf 等等,都是向量化的。
也支援其他常用的方法
>>> norm.mean(), norm.std(), norm.var()
(0.0, 1.0, 1.0)
>>> norm.stats(moments="mv")
(array(0.0), array(1.0))
要找到分佈的中位數,我們可以使用百分點函數 ppf,它是 cdf 的反函數
>>> norm.ppf(0.5)
0.0
要產生隨機變量的序列,請使用 size 關鍵字引數
>>> norm.rvs(size=3)
array([-0.35687759, 1.34347647, -0.11710531]) # random
不要認為 norm.rvs(5) 會產生 5 個變量
>>> norm.rvs(5)
5.471435163732493 # random
在這裡,沒有關鍵字的 5 被解釋為第一個可能的關鍵字引數 loc,它是所有連續分佈採用的成對關鍵字引數中的第一個。這將我們帶到下一個小節的主題。
隨機數生成#
繪製隨機數依賴於 numpy.random 套件中的生成器。在上面的範例中,隨機數的特定流在執行之間不可重現。為了實現可重現性,您可以明確地播種隨機數生成器。在 NumPy 中,生成器是 numpy.random.Generator 的實例。以下是建立生成器的標準方法
>>> from numpy.random import default_rng
>>> rng = default_rng()
而固定種子可以這樣做
>>> # do NOT copy this value
>>> rng = default_rng(301439351238479871608357552876690613766)
警告
請勿使用此數字或常見值(例如 0)。僅使用一小組種子來實例化更大的狀態空間意味著有些初始狀態無法達到。如果每個人都使用這些值,則會產生一些偏差。取得種子的好方法是使用 numpy.random.SeedSequence
>>> from numpy.random import SeedSequence
>>> print(SeedSequence().entropy)
301439351238479871608357552876690613766 # random
分佈中的 random_state 參數接受 numpy.random.Generator 類別的實例,或一個整數,然後用於播種內部 Generator 物件
>>> norm.rvs(size=5, random_state=rng)
array([ 0.47143516, -1.19097569, 1.43270697, -0.3126519 , -0.72058873]) # random
如需更多資訊,請參閱 NumPy 的文件。
要了解有關 SciPy 中實作的隨機數取樣器的更多資訊,請參閱 非均勻隨機數取樣教學 和 準蒙地卡羅教學
位移和縮放#
所有連續分佈都採用 loc 和 scale 作為關鍵字參數,以調整分佈的位置和尺度,例如,對於標準常態分佈,位置是平均值,尺度是標準差。
>>> norm.stats(loc=3, scale=4, moments="mv")
(array(3.0), array(16.0))
在許多情況下,隨機變數 X 的標準化分佈是透過轉換 (X - loc) / scale 獲得的。預設值為 loc = 0 和 scale = 1。
聰明地使用 loc 和 scale 可以幫助以多種方式修改標準分佈。為了進一步說明縮放,平均值為 \(1/\lambda\) 的指數分佈 RV 的 cdf 由下式給出
透過應用上面的縮放規則,可以看出透過取 scale = 1./lambda,我們得到適當的尺度。
>>> from scipy.stats import expon
>>> expon.mean(scale=3.)
3.0
注意
採用形狀參數的分佈可能需要比簡單應用 loc 和/或 scale 更複雜的操作才能達到所需的形狀。例如,在給定長度為 \(R\) 的常數向量的情況下,由每個分量中獨立的 N(0, \(\sigma^2\)) 偏差擾動的 2-D 向量長度的分佈是 rice(\(R/\sigma\), scale= \(\sigma\))。第一個引數是一個形狀參數,需要與 \(x\) 一起縮放。
均勻分佈也很有趣
>>> from scipy.stats import uniform
>>> uniform.cdf([0, 1, 2, 3, 4, 5], loc=1, scale=4)
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])
最後,回想一下上一段,我們仍然面臨 norm.rvs(5) 含義的問題。事實證明,像這樣呼叫分佈,第一個引數(即 5)會傳遞以設定 loc 參數。讓我們看看
>>> np.mean(norm.rvs(5, size=500))
5.0098355106969992 # random
因此,為了說明上一節範例的輸出:norm.rvs(5) 產生一個平均值為 loc=5 的單個常態分佈隨機變量,因為預設的 size=1。
我們建議您明確設定 loc 和 scale 參數,方法是將值作為關鍵字而不是作為引數傳遞。當呼叫給定 RV 的多個方法時,可以使用 凍結分佈 的技術來最小化重複,如下所述。
形狀參數#
雖然可以使用 loc 和 scale 參數來位移和縮放一般連續隨機變數,但有些分佈需要額外的形狀參數。例如,密度為
的伽瑪分佈需要形狀參數 \(a\)。請注意,設定 \(\lambda\) 可以透過將 scale 關鍵字設定為 \(1/\lambda\) 來獲得。
讓我們檢查伽瑪分佈的形狀參數的數量和名稱。(我們從上面知道這應該是 1。)
>>> from scipy.stats import gamma
>>> gamma.numargs
1
>>> gamma.shapes
'a'
現在,我們將形狀變數的值設定為 1 以獲得指數分佈,以便我們可以輕鬆比較我們是否獲得了預期的結果。
>>> gamma(1, scale=2.).stats(moments="mv")
(array(2.0), array(4.0))
請注意,我們也可以將形狀參數指定為關鍵字
>>> gamma(a=1, scale=2.).stats(moments="mv")
(array(2.0), array(4.0))
凍結分佈#
一遍又一遍地傳遞 loc 和 scale 關鍵字可能會變得非常麻煩。 凍結 RV 的概念用於解決此類問題。
>>> rv = gamma(1, scale=2.)
透過使用 rv,我們不再需要包含尺度或形狀參數。因此,分佈可以使用兩種方式之一,一種是將所有分佈參數傳遞給每個方法呼叫(就像我們之前所做的那樣),另一種是凍結分佈實例的參數。讓我們檢查一下
>>> rv.mean(), rv.std()
(2.0, 2.0)
這確實是我們應該得到的。
廣播#
基本方法 pdf 等等,符合常用的 numpy 廣播規則。例如,我們可以計算 t 分佈上尾的不同機率和自由度的臨界值。
>>> stats.t.isf([0.1, 0.05, 0.01], [[10], [11]])
array([[ 1.37218364, 1.81246112, 2.76376946],
[ 1.36343032, 1.79588482, 2.71807918]])
在這裡,第一列包含 10 個自由度的臨界值,第二列包含 11 個自由度的臨界值(d.o.f.)。因此,廣播規則給出了與呼叫 isf 兩次相同的結果
>>> stats.t.isf([0.1, 0.05, 0.01], 10)
array([ 1.37218364, 1.81246112, 2.76376946])
>>> stats.t.isf([0.1, 0.05, 0.01], 11)
array([ 1.36343032, 1.79588482, 2.71807918])
如果具有機率的陣列(即 [0.1, 0.05, 0.01])和自由度陣列(即 [10, 11, 12])具有相同的陣列形狀,則使用元素方式的匹配。例如,我們可以透過呼叫以下內容來獲得 10 個 d.o.f. 的 10% 尾部、11 個 d.o.f. 的 5% 尾部和 12 個 d.o.f. 的 1% 尾部
>>> stats.t.isf([0.1, 0.05, 0.01], [10, 11, 12])
array([ 1.37218364, 1.79588482, 2.68099799])
離散分佈的特定點#
離散分佈與連續分佈具有大多數相同的基本方法。但是,pdf 被機率質量函數 pmf 取代,沒有估計方法(例如 fit)可用,並且 scale 不是有效的關鍵字參數。位置參數(關鍵字 loc)仍然可以用於位移分佈。
cdf 的計算需要額外注意。在連續分佈的情況下,累積分佈函數在大多數標準情況下,在邊界 (a,b) 中嚴格單調遞增,因此具有唯一的反函數。但是,離散分佈的 cdf 是階梯函數,因此反 cdf(即百分點函數)需要不同的定義
ppf(q) = min{x : cdf(x) >= q, x integer}
如需更多資訊,請參閱 此處 的文件。
我們可以查看超幾何分佈作為範例
>>> from scipy.stats import hypergeom
>>> [M, n, N] = [20, 7, 12]
如果我們在某些整數點使用 cdf,然後在這些 cdf 值處評估 ppf,我們會得到初始整數,例如
>>> x = np.arange(4) * 2
>>> x
array([0, 2, 4, 6])
>>> prb = hypergeom.cdf(x, M, n, N)
>>> prb
array([ 1.03199174e-04, 5.21155831e-02, 6.08359133e-01,
9.89783282e-01])
>>> hypergeom.ppf(prb, M, n, N)
array([ 0., 2., 4., 6.])
如果我們使用不在 cdf 階梯函數扭結處的值,我們會得到下一個更高的整數
>>> hypergeom.ppf(prb + 1e-8, M, n, N)
array([ 1., 3., 5., 7.])
>>> hypergeom.ppf(prb - 1e-8, M, n, N)
array([ 0., 2., 4., 6.])
擬合分佈#
非凍結分佈的主要附加方法與分佈參數的估計有關
- fit:分佈參數的最大似然估計,包括位置
和尺度
fit_loc_scale:給定形狀參數時的位置和尺度估計
nnlf:負對數似然函數
expect:計算函數對於 pdf 或 pmf 的期望值
效能問題和警示性說明#
就速度而言,各個方法的效能因分佈和方法而異。方法的結果以兩種方式之一獲得:透過顯式計算,或透過獨立於特定分佈的通用演算法。
另一方面,顯式計算要求該方法直接針對給定的分佈指定,無論是透過解析公式還是透過 scipy.special 或 numpy.random 中的特殊函數(對於 rvs)。這些通常是相對快速的計算。
另一方面,如果分佈未指定任何顯式計算,則使用通用方法。要定義分佈,只需要 pdf 或 cdf 中的一個;所有其他方法都可以使用數值積分和求根來推導。但是,這些間接方法可能非常慢。例如,rgh = stats.gausshyper.rvs(0.5, 2, 2, 2, size=100) 以非常間接的方式建立隨機變數,在我的電腦上產生 100 個隨機變數大約需要 19 秒,而來自標準常態分佈或 t 分佈的一百萬個隨機變數僅需一秒多一點的時間。
剩餘問題#
scipy.stats 中的分佈最近已得到更正和改進,並獲得了相當大的測試套件;但是,仍然存在一些問題
分佈已在某些參數範圍內進行了測試;但是,在某些角落範圍內,可能仍然存在一些不正確的結果。
fit 中的最大似然估計不適用於所有分佈的預設起始參數,並且使用者需要提供良好的起始參數。此外,對於某些分佈,使用最大似然估計器可能本質上不是最佳選擇。
建置特定分佈#
下一個範例示範如何建置您自己的分佈。更多範例示範了分佈的用法和一些統計檢定。
建立連續分佈,即子類別化 rv_continuous#
建立連續分佈相當簡單。
>>> from scipy import stats
>>> class deterministic_gen(stats.rv_continuous):
... def _cdf(self, x):
... return np.where(x < 0, 0., 1.)
... def _stats(self):
... return 0., 0., 0., 0.
>>> deterministic = deterministic_gen(name="deterministic")
>>> deterministic.cdf(np.arange(-3, 3, 0.5))
array([ 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1.])
有趣的是,現在會自動計算 pdf
>>> deterministic.pdf(np.arange(-3, 3, 0.5))
array([ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
5.83333333e+04, 4.16333634e-12, 4.16333634e-12,
4.16333634e-12, 4.16333634e-12, 4.16333634e-12])
請注意效能問題和警示性說明中提到的效能問題。未指定常用方法的計算可能會變得非常慢,因為僅呼叫通用方法,這些方法本質上無法使用有關分佈的任何特定資訊。因此,作為一個警示性範例
>>> from scipy.integrate import quad
>>> quad(deterministic.pdf, -1e-1, 1e-1)
(4.163336342344337e-13, 0.0)
但這是錯誤的:此 pdf 的積分應為 1。讓我們將積分間隔縮小
>>> quad(deterministic.pdf, -1e-3, 1e-3) # warning removed
(1.000076872229173, 0.0010625571718182458)
這看起來更好。但是,問題源於 pdf 未在確定性分佈的類別定義中指定的事實。
子類別化 rv_discrete#
在下文中,我們使用 stats.rv_discrete 來產生離散分佈,該分佈具有以整數為中心的間隔的截斷常態的機率。
一般資訊
從 rv_discrete 的 docstring,help(stats.rv_discrete),
“您可以透過將序列元組 (xk, pk) 傳遞給 rv_discrete 初始化方法(透過 values= 關鍵字),來建構任意離散 rv,其中 P{X=xk} = pk,該元組僅描述 X (xk) 的那些值,這些值以非零機率 (pk) 出現。”
除此之外,此方法還需要一些其他要求才能運作
關鍵字 name 是必需的。
分佈 xk 的支援點必須是整數。
需要指定有效位數(小數位)。
實際上,如果最後兩個要求未滿足,則可能會引發例外,或者產生的數字可能不正確。
範例
讓我們開始工作。首先
>>> npoints = 20 # number of integer support points of the distribution minus 1
>>> npointsh = npoints // 2
>>> npointsf = float(npoints)
>>> nbound = 4 # bounds for the truncated normal
>>> normbound = (1+1/npointsf) * nbound # actual bounds of truncated normal
>>> grid = np.arange(-npointsh, npointsh+2, 1) # integer grid
>>> gridlimitsnorm = (grid-0.5) / npointsh * nbound # bin limits for the truncnorm
>>> gridlimits = grid - 0.5 # used later in the analysis
>>> grid = grid[:-1]
>>> probs = np.diff(stats.truncnorm.cdf(gridlimitsnorm, -normbound, normbound))
>>> gridint = grid
最後,我們可以子類別化 rv_discrete
>>> normdiscrete = stats.rv_discrete(values=(gridint,
... np.round(probs, decimals=7)), name='normdiscrete')
現在我們已經定義了分佈,我們可以存取離散分佈的所有常用方法。
>>> print('mean = %6.4f, variance = %6.4f, skew = %6.4f, kurtosis = %6.4f' %
... normdiscrete.stats(moments='mvsk'))
mean = -0.0000, variance = 6.3302, skew = 0.0000, kurtosis = -0.0076
>>> nd_std = np.sqrt(normdiscrete.stats(moments='v'))
測試實作
讓我們產生一個隨機樣本,並將觀察到的頻率與機率進行比較。
>>> n_sample = 500
>>> rvs = normdiscrete.rvs(size=n_sample)
>>> f, l = np.histogram(rvs, bins=gridlimits)
>>> sfreq = np.vstack([gridint, f, probs*n_sample]).T
>>> print(sfreq)
[[-1.00000000e+01 0.00000000e+00 2.95019349e-02] # random
[-9.00000000e+00 0.00000000e+00 1.32294142e-01]
[-8.00000000e+00 0.00000000e+00 5.06497902e-01]
[-7.00000000e+00 2.00000000e+00 1.65568919e+00]
[-6.00000000e+00 1.00000000e+00 4.62125309e+00]
[-5.00000000e+00 9.00000000e+00 1.10137298e+01]
[-4.00000000e+00 2.60000000e+01 2.24137683e+01]
[-3.00000000e+00 3.70000000e+01 3.89503370e+01]
[-2.00000000e+00 5.10000000e+01 5.78004747e+01]
[-1.00000000e+00 7.10000000e+01 7.32455414e+01]
[ 0.00000000e+00 7.40000000e+01 7.92618251e+01]
[ 1.00000000e+00 8.90000000e+01 7.32455414e+01]
[ 2.00000000e+00 5.50000000e+01 5.78004747e+01]
[ 3.00000000e+00 5.00000000e+01 3.89503370e+01]
[ 4.00000000e+00 1.70000000e+01 2.24137683e+01]
[ 5.00000000e+00 1.10000000e+01 1.10137298e+01]
[ 6.00000000e+00 4.00000000e+00 4.62125309e+00]
[ 7.00000000e+00 3.00000000e+00 1.65568919e+00]
[ 8.00000000e+00 0.00000000e+00 5.06497902e-01]
[ 9.00000000e+00 0.00000000e+00 1.32294142e-01]
[ 1.00000000e+01 0.00000000e+00 2.95019349e-02]]
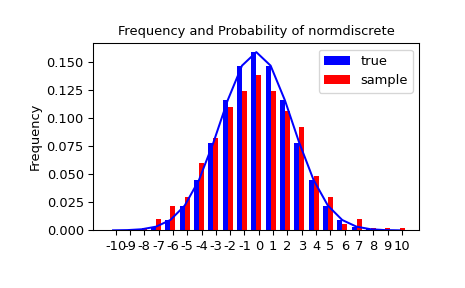
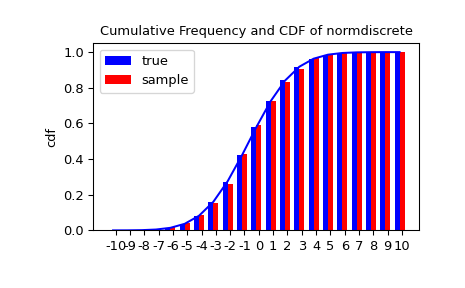
接下來,我們可以使用卡方檢定 scipy.stats.chisquare,來檢定樣本是否根據我們的常態離散分佈分佈的虛無假設。
檢定要求每個 bin 中有最少數量的觀察值。我們將尾部 bin 合併為更大的 bin,以便它們包含足夠的觀察值。
>>> f2 = np.hstack([f[:5].sum(), f[5:-5], f[-5:].sum()])
>>> p2 = np.hstack([probs[:5].sum(), probs[5:-5], probs[-5:].sum()])
>>> ch2, pval = stats.chisquare(f2, p2*n_sample)
>>> print('chisquare for normdiscrete: chi2 = %6.3f pvalue = %6.4f' % (ch2, pval))
chisquare for normdiscrete: chi2 = 12.466 pvalue = 0.4090 # random
從概念上講,檢定統計量 chi2 對觀察頻率與虛無假設下的預期頻率之間的偏差很敏感。p 值是從假設的分佈中抽取樣本的機率,這些樣本將產生比我們觀察到的統計值更極端的值。我們的統計值不是很高;事實上,如果我們要從 p2 定義的離散分佈中抽取相同大小的樣本,則統計量高於 12.466 的機率為 40.9%。因此,檢定幾乎沒有提供證據反對樣本是從我們的常態離散分佈中抽取的虛無假設。