準蒙地卡羅#
在討論準蒙地卡羅 (QMC) 之前,先快速介紹一下蒙地卡羅 (MC)。蒙地卡羅方法或蒙地卡羅實驗是一大類計算演算法,它們依賴重複的隨機抽樣來獲得數值結果。其基本概念是使用隨機性來解決原則上可能是確定性的問題。它們通常用於物理和數學問題,並且在難以或不可能使用其他方法時最有用。蒙地卡羅方法主要用於三個問題類別:最佳化、數值積分和從機率分佈中產生抽樣。
產生具有特定屬性的隨機數字比聽起來更複雜。簡單的蒙地卡羅方法旨在對點進行抽樣,使其成為獨立且恆等分佈 (IID)。但是,產生多組隨機點可能會產生截然不同的結果。
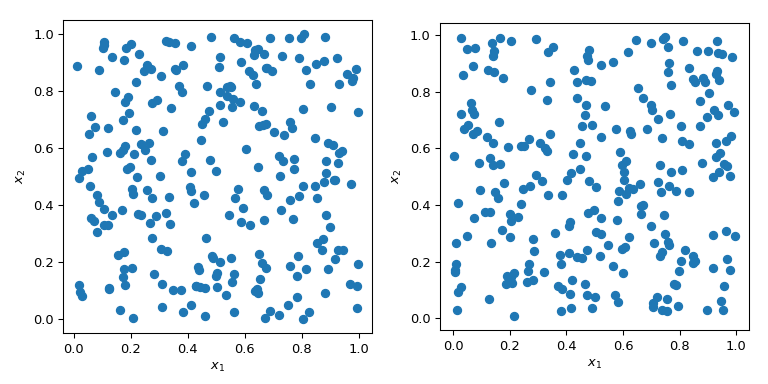
在上面圖中的兩種情況下,點都是隨機產生的,而沒有關於先前繪製點的任何知識。顯然,空間的某些區域未被探索——這可能會在模擬中引起問題,因為一組特定的點可能會觸發完全不同的行為。
蒙地卡羅的一個巨大優勢是它具有已知的收斂特性。讓我們看看 5 維中平方和的平均值
其中 \(x_j \sim \mathcal{U}(0,1)\)。它具有已知的平均值 \(\mu = 5/3+5(5-1)/4\)。使用蒙地卡羅抽樣,我們可以數值計算該平均值,並且近似誤差遵循 \(O(n^{-1/2})\) 的理論速率。
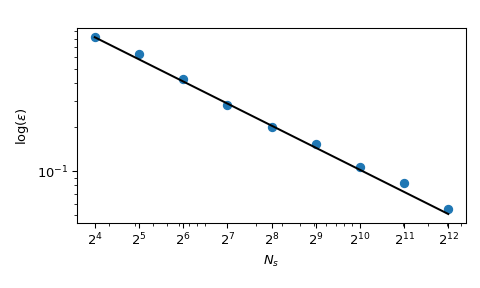
雖然收斂性得到保證,但實務人員傾向於希望有一個更具決定性的探索過程。使用普通的蒙地卡羅,可以使用種子來獲得可重複的過程。但是,固定種子會破壞收斂性:給定的種子可能適用於給定類別的問題,但會破壞另一個問題。
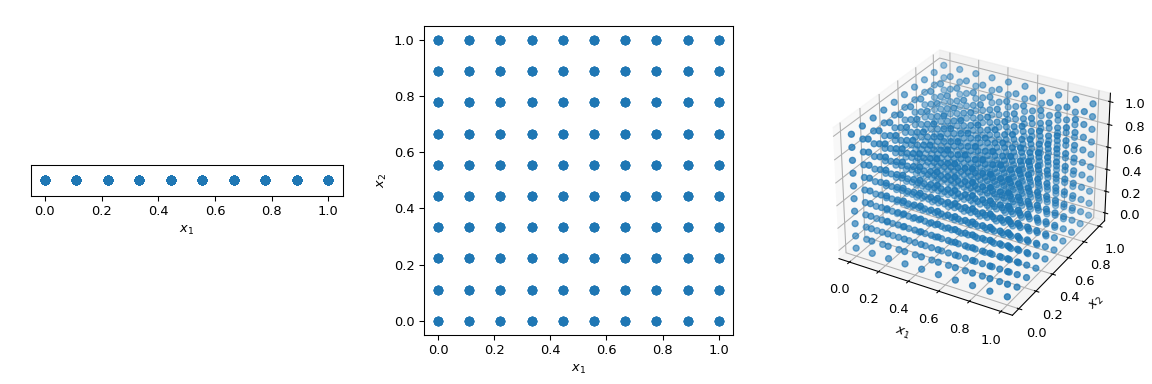
為了以確定性的方式遍歷空間,通常的做法是使用跨越所有參數維度的規則網格,也稱為飽和設計。讓我們考慮單位超立方體,所有邊界範圍從 0 到 1。現在,點之間的距離為 0.1,填充單位間隔所需的點數為 10。在二維超立方體中,相同的間距將需要 100 個點,在 3 維中需要 1,000 個點。隨著維數的增長,填充空間所需的實驗次數呈指數級增長,因為空間的維數增加。這種指數級增長稱為「維度詛咒」。
>>> import numpy as np
>>> disc = 10
>>> x1 = np.linspace(0, 1, disc)
>>> x2 = np.linspace(0, 1, disc)
>>> x3 = np.linspace(0, 1, disc)
>>> x1, x2, x3 = np.meshgrid(x1, x2, x3)
為了減輕這個問題,設計了準蒙地卡羅方法。它們是確定性的,對空間有良好的覆蓋率,並且其中一些可以繼續並保持良好的特性。與蒙地卡羅方法的主要區別在於,這些點不是 IID,但它們知道先前的點。因此,某些方法也稱為序列。
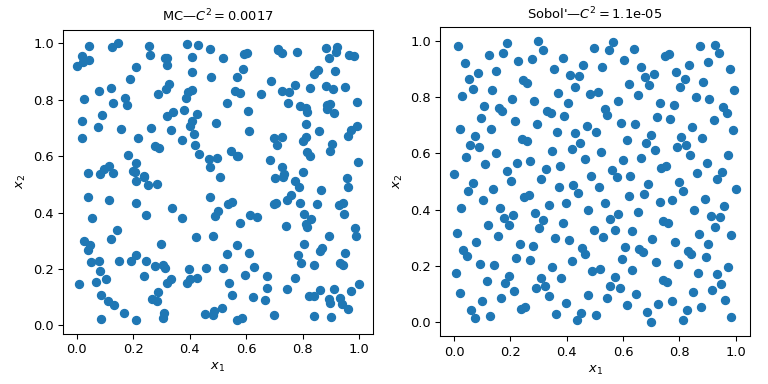
此圖呈現了 2 組 256 個點。左側的設計是普通的蒙地卡羅,而右側的設計是使用Sobol’方法的準蒙地卡羅設計。我們清楚地看到準蒙地卡羅版本更均勻。這些點在邊界附近採樣得更好,並且叢集或間隙更少。
評估均勻性的一種方法是使用稱為差異度的度量。這裡,Sobol’點的差異度優於原始蒙地卡羅。
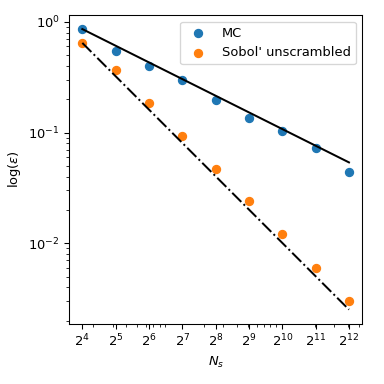
回到平均值的計算,準蒙地卡羅方法也具有更好的誤差收斂率。對於此函數,它們可以達到 \(O(n^{-1})\),甚至在非常平滑的函數上可以達到更好的速率。此圖顯示 Sobol’ 方法的速率為 \(O(n^{-1})\)
有關更多數學細節,請參閱 scipy.stats.qmc 的文件。
計算差異度#
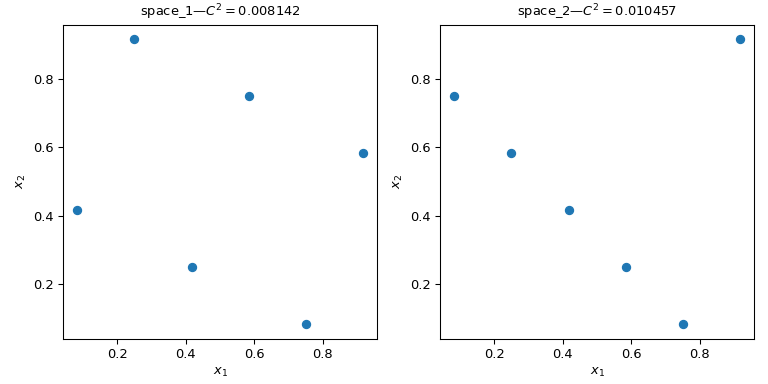
讓我們考慮兩組點。從下圖中可以清楚地看出,左側的設計比右側的設計覆蓋了更多的空間。這可以使用 scipy.stats.qmc.discrepancy 度量來量化。差異度越低,樣本越均勻。
>>> import numpy as np
>>> from scipy.stats import qmc
>>> space_1 = np.array([[1, 3], [2, 6], [3, 2], [4, 5], [5, 1], [6, 4]])
>>> space_2 = np.array([[1, 5], [2, 4], [3, 3], [4, 2], [5, 1], [6, 6]])
>>> l_bounds = [0.5, 0.5]
>>> u_bounds = [6.5, 6.5]
>>> space_1 = qmc.scale(space_1, l_bounds, u_bounds, reverse=True)
>>> space_2 = qmc.scale(space_2, l_bounds, u_bounds, reverse=True)
>>> qmc.discrepancy(space_1)
0.008142039609053464
>>> qmc.discrepancy(space_2)
0.010456854423869011
使用準蒙地卡羅引擎#
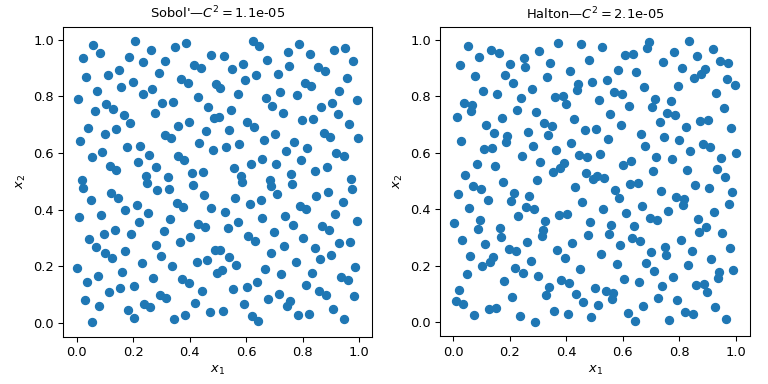
實作了幾個準蒙地卡羅取樣器/引擎。在這裡,我們看看兩個最常用的準蒙地卡羅方法:scipy.stats.qmc.Sobol 和 scipy.stats.qmc.Halton 序列。
"""Sobol' and Halton sequences."""
from scipy.stats import qmc
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng()
n_sample = 256
dim = 2
sample = {}
# Sobol'
engine = qmc.Sobol(d=dim, seed=rng)
sample["Sobol'"] = engine.random(n_sample)
# Halton
engine = qmc.Halton(d=dim, seed=rng)
sample["Halton"] = engine.random(n_sample)
fig, axs = plt.subplots(1, 2, figsize=(8, 4))
for i, kind in enumerate(sample):
axs[i].scatter(sample[kind][:, 0], sample[kind][:, 1])
axs[i].set_aspect('equal')
axs[i].set_xlabel(r'$x_1$')
axs[i].set_ylabel(r'$x_2$')
axs[i].set_title(f'{kind}—$C^2 = ${qmc.discrepancy(sample[kind]):.2}')
plt.tight_layout()
plt.show()
警告
準蒙地卡羅方法需要特別小心,使用者必須閱讀文件以避免常見的陷阱。例如,Sobol’ 需要點數為 2 的冪次方。此外,稀疏化、燒錄或其他點選擇可能會破壞序列的屬性,並導致一組點不如蒙地卡羅。
準蒙地卡羅引擎是狀態感知的。這意味著您可以繼續序列、跳過某些點或重置它。讓我們從 scipy.stats.qmc.Halton 中取 5 個點。然後要求第二組 5 個點
>>> from scipy.stats import qmc
>>> engine = qmc.Halton(d=2)
>>> engine.random(5)
array([[0.22166437, 0.07980522], # random
[0.72166437, 0.93165708],
[0.47166437, 0.41313856],
[0.97166437, 0.19091633],
[0.01853937, 0.74647189]])
>>> engine.random(5)
array([[0.51853937, 0.52424967], # random
[0.26853937, 0.30202745],
[0.76853937, 0.857583 ],
[0.14353937, 0.63536078],
[0.64353937, 0.01807683]])
現在我們重置序列。要求 5 個點會導致相同的前 5 個點
>>> engine.reset()
>>> engine.random(5)
array([[0.22166437, 0.07980522], # random
[0.72166437, 0.93165708],
[0.47166437, 0.41313856],
[0.97166437, 0.19091633],
[0.01853937, 0.74647189]])
在這裡,我們推進序列以獲得相同的第二組 5 個點
>>> engine.reset()
>>> engine.fast_forward(5)
>>> engine.random(5)
array([[0.51853937, 0.52424967], # random
[0.26853937, 0.30202745],
[0.76853937, 0.857583 ],
[0.14353937, 0.63536078],
[0.64353937, 0.01807683]])
注意
預設情況下,scipy.stats.qmc.Sobol 和 scipy.stats.qmc.Halton 都經過擾亂。收斂特性更好,並且可以防止在高維度中出現條紋或明顯的點模式。應該沒有實際理由不使用擾亂版本。
建立準蒙地卡羅引擎,即子類化 QMCEngine#
為了建立您自己的 scipy.stats.qmc.QMCEngine,必須定義一些方法。以下是封裝 numpy.random.Generator 的範例。
>>> import numpy as np
>>> from scipy.stats import qmc
>>> class RandomEngine(qmc.QMCEngine):
... def __init__(self, d, seed=None):
... super().__init__(d=d, seed=seed)
... self.rng = np.random.default_rng(self.rng_seed)
...
...
... def _random(self, n=1, *, workers=1):
... return self.rng.random((n, self.d))
...
...
... def reset(self):
... self.rng = np.random.default_rng(self.rng_seed)
... self.num_generated = 0
... return self
...
...
... def fast_forward(self, n):
... self.random(n)
... return self
然後我們像使用任何其他準蒙地卡羅引擎一樣使用它
>>> engine = RandomEngine(2)
>>> engine.random(5)
array([[0.22733602, 0.31675834], # random
[0.79736546, 0.67625467],
[0.39110955, 0.33281393],
[0.59830875, 0.18673419],
[0.67275604, 0.94180287]])
>>> engine.reset()
>>> engine.random(5)
array([[0.22733602, 0.31675834], # random
[0.79736546, 0.67625467],
[0.39110955, 0.33281393],
[0.59830875, 0.18673419],
[0.67275604, 0.94180287]])
使用準蒙地卡羅的指南#
準蒙地卡羅有規則!請務必閱讀文件,否則您可能無法獲得優於蒙地卡羅的任何好處。
如果您需要正好 \(2^m\) 個點,請使用
scipy.stats.qmc.Sobol。scipy.stats.qmc.Halton允許取樣或跳過任意數量的點。這是以比 Sobol’ 更慢的收斂速度為代價的。永遠不要移除序列的第一個點。它會破壞屬性。
擾亂總是更好。
如果您使用基於 LHS 的方法,則無法在不失去 LHS 屬性的情況下新增點。(有一些方法可以做到這一點,但尚未實作。)