derivative#
- scipy.differentiate.derivative(f, x, *, args=(), tolerances=None, maxiter=10, order=8, initial_step=0.5, step_factor=2.0, step_direction=0, preserve_shape=False, callback=None)[原始碼]#
以數值方式評估逐元素實數純量函數的導數。
對於 f 的每個輸出元素,
derivative使用有限差分微分逼近 f 在 x 對應元素處的一階導數。當 x、step_direction 和 args 包含(可廣播的)陣列時,此函數會逐元素運作。
- 參數:
- f可呼叫物件
想要計算導數的函數。簽名檔必須是
f(xi: ndarray, *argsi) -> ndarray
其中
xi的每個元素都是有限實數,而argsi是一個元組,其中可能包含任意數量的陣列,這些陣列可與xi廣播。f 必須是逐元素函數:每個純量元素f(xi)[j]必須等於有效索引j的f(xi[j])。它不得變更陣列xi或argsi中的陣列。- x浮點數 array_like
用於評估導數的橫座標。必須可與 args 和 step_direction 廣播。
- argsarray_like 元組,選用
要傳遞給 f 的其他位置陣列引數。陣列必須彼此以及 init 的陣列可廣播。如果想要尋找根的可呼叫物件需要無法與 x 廣播的引數,請使用 f 包裝該可呼叫物件,以便 f 僅接受 x 和可廣播的
*args。- tolerances浮點數字典,選用
絕對和相對容差。字典的有效鍵為
atol- 導數的絕對容差rtol- 導數的相對容差
當
res.error < atol + rtol * abs(res.df)時,迭代將停止。預設 atol 是適當 dtype 的最小正常數,而預設 rtol 是適當 dtype 精確度的平方根。- order整數,預設值:8
要使用的有限差分公式的(正整數)階數。奇數整數將四捨五入為下一個偶數整數。
- initial_step浮點數 array_like,預設值:0.5
有限差分導數逼近的(絕對)初始步長。
- step_factor浮點數,預設值:2.0
每次迭代中縮減步長的因數;即,迭代 1 中的步長為
initial_step/step_factor。如果step_factor < 1,則後續步驟將大於初始步驟;如果小於某個閾值的步驟是不理想的(例如,由於減法抵消錯誤),這可能很有用。- maxiter整數,預設值:10
要執行的演算法最大迭代次數。請參閱「注意事項」。
- step_direction整數 array_like
表示有限差分步長方向的陣列(當 x 靠近函數域的邊界時使用。)必須可與 x 和所有 args 廣播。其中 0(預設值),使用中心差分;其中負數(例如 -1),步長為非正數;其中正數(例如 1),所有步長為非負數。
- preserve_shape布林值,預設值:False
在下文中,「f 的引數」是指陣列
xi和argsi中的任何陣列。令shape為 x 和 args 所有元素(在概念上與傳遞到 f 的xi` 和 ``argsi不同)的廣播形狀。當
preserve_shape=False(預設值)時,f 必須接受任何可廣播形狀的引數。當
preserve_shape=True時,f 必須接受形狀為shape或shape + (n,)的引數,其中(n,)是評估函數時的橫座標數。
在任一情況下,對於
xi內部的每個純量元素xi[j],f 傳回的陣列必須在相同索引處包含純量f(xi[j])。因此,輸出的形狀始終是輸入xi的形狀。請參閱「範例」。
- callback可呼叫物件,選用
要在第一次迭代之前和每次迭代之後呼叫的選用使用者提供函數。呼叫方式為
callback(res),其中res是類似於derivative傳回的_RichResult(但包含所有變數的目前迭代值)。如果 callback 引發StopIteration,則演算法將立即終止,且derivative將傳回結果。callback 不得變更 res 或其屬性。
- 回傳:
- res_RichResult
類似於
scipy.optimize.OptimizeResult執行個體的物件,具有以下屬性。描述的撰寫方式就好像值是純量一樣;但是,如果 f 傳回陣列,則輸出將是相同形狀的陣列。- success布林值陣列
演算法成功終止時為
True(狀態0);否則為False。- status整數陣列
表示演算法結束狀態的整數。
0: 演算法收斂到指定的容差。-1: 錯誤估計值增加,因此迭代終止。-2: 已達到最大迭代次數。-3: 遇到非有限值。-4: 迭代由 callback 終止。1: 演算法正常進行中(僅在 callback 中)。
- df浮點數陣列
如果演算法成功終止,則為 f 在 x 處的導數。
- error浮點數陣列
錯誤估計值:導數的目前估計值與前一次迭代中的估計值之間的差值大小。
- nit整數陣列
執行的演算法迭代次數。
- nfev整數陣列
評估 f 的點數。
- x浮點數陣列
評估 f 導數的值(與 args 和 step_direction 廣播後)。
說明
此實作的靈感來自 jacobi [1]、numdifftools [2] 和 DERIVEST [3],但此實作更直接(且可說是天真地)遵循泰勒級數理論。在第一次迭代中,使用階數為 order 且最大步長為 initial_step 的有限差分公式估計導數。在每次後續迭代中,最大步長會縮減 step_factor,並再次估計導數,直到達到終止條件。錯誤估計值是目前導數逼近值與前一次迭代的導數逼近值之間差值的大小。
有限差分公式的模板設計為使橫座標「巢狀」:在第一次迭代中於
order + 1個點評估 f 後,在每次後續迭代中僅於兩個新點評估 f;有限差分公式所需的order - 1個先前評估的函數值會重複使用,而兩個函數值(在離 x 最遠的點評估)則未使用。步長是絕對的。當步長相對於 x 的大小較小時,精確度會降低;例如,如果 x 為
1e20,則無法解析預設初始步長0.5。因此,請考慮針對 x 的較大大小使用較大的初始步長。預設容差在真導數正好為零的點難以滿足。如果導數可能正好為零,請考慮指定絕對容差(例如
atol=1e-12)以改善收斂性。參考文獻
[1]Hans Dembinski (@HDembinski)。jacobi。HDembinski/jacobi
[2]Per A. Brodtkorb 和 John D’Errico。numdifftools。https://numdifftools.readthedocs.io/en/latest/
[3]John D’Errico。DERIVEST:自適應穩健數值微分。https://www.mathworks.com/matlabcentral/fileexchange/13490-adaptive-robust-numerical-differentiation
[4]數值微分。維基百科。https://en.wikipedia.org/wiki/Numerical_differentiation
範例
評估
np.exp在幾個點x的導數。>>> import numpy as np >>> from scipy.differentiate import derivative >>> f = np.exp >>> df = np.exp # true derivative >>> x = np.linspace(1, 2, 5) >>> res = derivative(f, x) >>> res.df # approximation of the derivative array([2.71828183, 3.49034296, 4.48168907, 5.75460268, 7.3890561 ]) >>> res.error # estimate of the error array([7.13740178e-12, 9.16600129e-12, 1.17594823e-11, 1.51061386e-11, 1.94262384e-11]) >>> abs(res.df - df(x)) # true error array([2.53130850e-14, 3.55271368e-14, 5.77315973e-14, 5.59552404e-14, 6.92779167e-14])
顯示逼近值在步長縮減時的收斂性。每次迭代,步長都會縮減 step_factor,因此對於足夠小的初始步長,每次迭代都會將誤差縮減
1/step_factor**order倍,直到有限精確度算術抑制進一步改善。>>> import matplotlib.pyplot as plt >>> iter = list(range(1, 12)) # maximum iterations >>> hfac = 2 # step size reduction per iteration >>> hdir = [-1, 0, 1] # compare left-, central-, and right- steps >>> order = 4 # order of differentiation formula >>> x = 1 >>> ref = df(x) >>> errors = [] # true error >>> for i in iter: ... res = derivative(f, x, maxiter=i, step_factor=hfac, ... step_direction=hdir, order=order, ... # prevent early termination ... tolerances=dict(atol=0, rtol=0)) ... errors.append(abs(res.df - ref)) >>> errors = np.array(errors) >>> plt.semilogy(iter, errors[:, 0], label='left differences') >>> plt.semilogy(iter, errors[:, 1], label='central differences') >>> plt.semilogy(iter, errors[:, 2], label='right differences') >>> plt.xlabel('iteration') >>> plt.ylabel('error') >>> plt.legend() >>> plt.show()
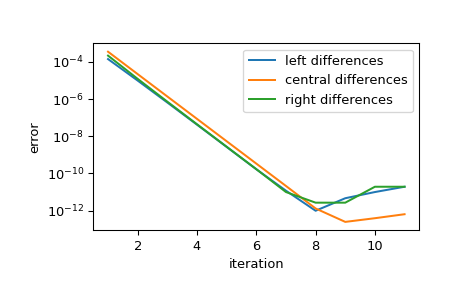
>>> (errors[1, 1] / errors[0, 1], 1 / hfac**order) (0.06215223140159822, 0.0625)
此實作已針對 x、step_direction 和 args 向量化。函數會在第一次迭代之前評估一次,以執行輸入驗證和標準化,然後在之後的每次迭代中評估一次。
>>> def f(x, p): ... f.nit += 1 ... return x**p >>> f.nit = 0 >>> def df(x, p): ... return p*x**(p-1) >>> x = np.arange(1, 5) >>> p = np.arange(1, 6).reshape((-1, 1)) >>> hdir = np.arange(-1, 2).reshape((-1, 1, 1)) >>> res = derivative(f, x, args=(p,), step_direction=hdir, maxiter=1) >>> np.allclose(res.df, df(x, p)) True >>> res.df.shape (3, 5, 4) >>> f.nit 2
預設情況下,preserve_shape 為 False,因此可呼叫物件 f 可以使用任何可廣播形狀的陣列呼叫。例如
>>> shapes = [] >>> def f(x, c): ... shape = np.broadcast_shapes(x.shape, c.shape) ... shapes.append(shape) ... return np.sin(c*x) >>> >>> c = [1, 5, 10, 20] >>> res = derivative(f, 0, args=(c,)) >>> shapes [(4,), (4, 8), (4, 2), (3, 2), (2, 2), (1, 2)]
若要瞭解這些形狀的來源,並更瞭解
derivative如何計算精確的結果,請注意,c的值越高,對應的正弦波頻率越高。正弦波頻率越高,函數的導數變化越快,因此需要更多函數評估才能達到目標精確度>>> res.nfev array([11, 13, 15, 17], dtype=int32)
初始
shape(4,)對應於在單個橫座標和所有四個頻率下評估函數;這用於輸入驗證並確定儲存結果的陣列的大小和 dtype。下一個形狀對應於在橫座標的初始網格和所有四個頻率下評估函數。對函數的後續呼叫會在兩個橫座標下評估函數,從而將逼近的有效階數增加 2。但是,在後續的函數評估中,函數在較少的頻率下評估,因為對應的導數已收斂到所需的容差。這樣可以節省函數評估以提高效能,但需要函數接受任何形狀的引數。「向量值」函數不太可能滿足此要求。例如,考慮
>>> def f(x): ... return [x, np.sin(3*x), x+np.sin(10*x), np.sin(20*x)*(x-1)**2]
此積分函數與已撰寫的
derivative不相容;例如,輸出的形狀將與x的形狀不同。這類函數可以透過引入其他參數來轉換為相容的形式,但這將很不方便。在這種情況下,更簡單的解決方案是使用 preserve_shape。>>> shapes = [] >>> def f(x): ... shapes.append(x.shape) ... x0, x1, x2, x3 = x ... return [x0, np.sin(3*x1), x2+np.sin(10*x2), np.sin(20*x3)*(x3-1)**2] >>> >>> x = np.zeros(4) >>> res = derivative(f, x, preserve_shape=True) >>> shapes [(4,), (4, 8), (4, 2), (4, 2), (4, 2), (4, 2)]
在這裡,
x的形狀為(4,)。使用preserve_shape=True,可以使用形狀為(4,)或(4, n)的引數呼叫函數,而這就是我們觀察到的。