kmeans#
- scipy.cluster.vq.kmeans(obs, k_or_guess, iter=20, thresh=1e-05, check_finite=True, *, rng=None)[原始碼]#
對一組觀測向量執行 k-means 演算法,形成 k 個群集。
k-means 演算法調整觀測值到群集的分類,並更新群集質心,直到質心的位置在連續迭代中穩定為止。在此演算法的實作中,質心的穩定性是透過比較觀測值與其對應質心之間平均歐幾里德距離變化的絕對值與閾值來判斷。這會產生一個程式碼簿,將質心映射到程式碼,反之亦然。
- 參數:
- obsndarray
M 乘 N 陣列的每一列都是一個觀測向量。這些列是在每次觀測期間看到的功能。這些功能必須先使用
whiten函數進行白化處理。- k_or_guessint 或 ndarray
要產生的質心數量。程式碼會指派給每個質心,這也是產生的 code_book 矩陣中質心的列索引。
初始 k 個質心是透過從觀測矩陣中隨機選擇觀測值來選取。或者,傳遞 k 乘 N 陣列會指定初始 k 個質心。
- iterint,選用
執行 k-means 的次數,傳回失真度最低的程式碼簿。如果使用
k_or_guess參數的陣列指定初始質心,則會忽略此引數。此參數不代表 k-means 演算法的迭代次數。- threshfloat,選用
如果自上次 k-means 迭代以來的失真度變化小於或等於閾值,則終止 k-means 演算法。
- check_finitebool,選用
是否檢查輸入矩陣是否僅包含有限數字。停用可能會提高效能,但如果輸入包含無限或 NaN,可能會導致問題(崩潰、非終止)。預設值:True
- rng{None, int,
numpy.random.Generator},選用 如果依關鍵字傳遞 rng,則除了
numpy.random.Generator以外的類型會傳遞至numpy.random.default_rng以實例化Generator。如果 rng 已經是Generator實例,則會使用提供的實例。指定 rng 以獲得可重複的函數行為。如果此引數依位置傳遞,或 seed 依關鍵字傳遞,則引數 seed 的舊版行為適用
如果 seed 為 None(或
numpy.random),則會使用numpy.random.RandomState單例模式。如果 seed 是整數,則會使用以 seed 作為種子的新
RandomState實例。如果 seed 已經是
Generator或RandomState實例,則會使用該實例。
在版本 1.15.0 中變更:作為從使用
numpy.random.RandomState過渡到numpy.random.Generator的 SPEC-007 轉換的一部分,此關鍵字已從 seed 變更為 rng。在過渡期間,seed 和 rng 兩個關鍵字將繼續運作,但一次只能指定一個。在過渡期之後,使用 seed 關鍵字的函數呼叫將發出警告。上面概述了 seed 和 rng 的行為,但新程式碼中應僅使用 rng 關鍵字。
- 傳回值:
- codebookndarray
k 乘 N 的 k 個質心陣列。第 i 個質心 codebook[i] 以程式碼 i 表示。產生的質心和程式碼代表看到的最低失真度,不一定是全域最小失真度。請注意,質心的數量不一定與
k_or_guess參數相同,因為在迭代期間會移除指派給無觀測值的質心。- distortionfloat
傳遞的觀測值與產生的質心之間的平均(非平方)歐幾里德距離。請注意,這與 k-means 演算法上下文中失真度的標準定義不同,後者是平方距離的總和。
註解
為了獲得更多功能或最佳效能,您可以使用 sklearn.cluster.KMeans。此處是多種實作的基準測試結果。
範例
>>> import numpy as np >>> from scipy.cluster.vq import vq, kmeans, whiten >>> import matplotlib.pyplot as plt >>> features = np.array([[ 1.9,2.3], ... [ 1.5,2.5], ... [ 0.8,0.6], ... [ 0.4,1.8], ... [ 0.1,0.1], ... [ 0.2,1.8], ... [ 2.0,0.5], ... [ 0.3,1.5], ... [ 1.0,1.0]]) >>> whitened = whiten(features) >>> book = np.array((whitened[0],whitened[2])) >>> kmeans(whitened,book) (array([[ 2.3110306 , 2.86287398], # random [ 0.93218041, 1.24398691]]), 0.85684700941625547)
>>> codes = 3 >>> kmeans(whitened,codes) (array([[ 2.3110306 , 2.86287398], # random [ 1.32544402, 0.65607529], [ 0.40782893, 2.02786907]]), 0.5196582527686241)
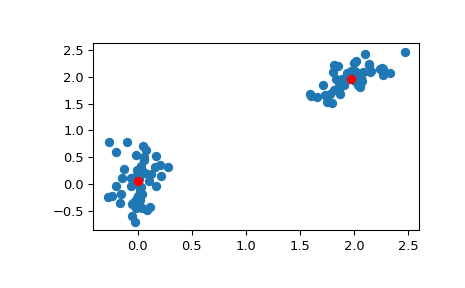
>>> # Create 50 datapoints in two clusters a and b >>> pts = 50 >>> rng = np.random.default_rng() >>> a = rng.multivariate_normal([0, 0], [[4, 1], [1, 4]], size=pts) >>> b = rng.multivariate_normal([30, 10], ... [[10, 2], [2, 1]], ... size=pts) >>> features = np.concatenate((a, b)) >>> # Whiten data >>> whitened = whiten(features) >>> # Find 2 clusters in the data >>> codebook, distortion = kmeans(whitened, 2) >>> # Plot whitened data and cluster centers in red >>> plt.scatter(whitened[:, 0], whitened[:, 1]) >>> plt.scatter(codebook[:, 0], codebook[:, 1], c='r') >>> plt.show()